
深度分析
RAG 醫療聊天機器人洩露風險:向量資料庫、API 配置與病患資料外洩實證
本文改寫自一項匿名安全評估,檢視一個公開可訪問的病患面向 RAG(檢索增強生成)醫療聊天機器人。研究採取非破壞性的兩階段方法,先以大型語言模型輔助探索可能漏洞,再用瀏覽器開發者工具逐項驗證。結果揭示系統透過瀏覽器可讀的客戶端–伺服器通訊洩露大量敏感設定與紀錄,包括完整 RAG 配置、知識庫內容與最近存檔的病患對話。
深度分析
本文改寫自一項匿名安全評估,檢視一個公開可訪問的病患面向 RAG(檢索增強生成)醫療聊天機器人。研究採取非破壞性的兩階段方法,先以大型語言模型輔助探索可能漏洞,再用瀏覽器開發者工具逐項驗證。結果揭示系統透過瀏覽器可讀的客戶端–伺服器通訊洩露大量敏感設定與紀錄,包括完整 RAG 配置、知識庫內容與最近存檔的病患對話。

深度分析
大數據平台運維面臨諮詢與診斷並存的挑戰。SiriusHelper以LLM驅動的路由器結合深度檢索與分層知識庫,實現多跳檢索與專家工作流自動導引,同時自動化票務理解並萃取SOP以持續擴充知識庫。上線後降低介接工單量。實驗與上線數據顯示相較替代方案提升答案可靠性與延遲表現,並將線上工單量降低20.8%。
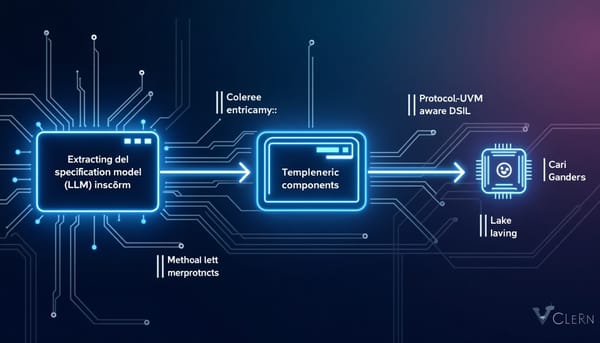
深度分析
IC驗證佔開發週期近七成,傳統手寫測試平台耗時龐大。研究提出HAVEN,結合LLM抽取規格與預先設計的Jinja2模板,並以協議感知的DSL產生序列,實現全自動UVM測試平台。實驗顯示在19個開源晶片上達到100%編譯成功、90.6%代碼覆蓋與87.9%功能覆蓋,顯著優於既有LLM方案。

深度分析
隨著具身AI逐漸突破感知瓶頸,研究提出ValuePlanner以LLM產生價值導向子目標,再由PDDL規劃器落實執行,實驗顯示其能在長期自主任務中協調衝突價值,產生更具一致性與多樣性的行為。此架構同時克服純神經模型的幻覺問題,並提供可驗證的行動計畫。

Moltis
Moltis是一以Rust開發的自托管個人AI代理伺服器,提供單一二進位檔、沙盒執行與多供應商LLM整合,支援語音、記憶、Telegram、Discord等平台。設計讓金鑰永不離機、程式碼可審計,已登上HackerNews首頁,顯示對本地安全AI代理的需求上升。

AIfred
AIfred Intelligence 是一個以 Python 為主的開源專案,提供本地化的多代理人工智慧助理。它支援工具呼叫、持續記憶、訊息中心與多代理辯論,並整合文字轉語音、語音辨識與網頁爬取等功能。使用者可在自有硬體上部署,免除雲端依賴,確保資料主權。

深度分析
開發者過去依賴索引層、查詢引擎等腳手架建構LLM應用,LlamaIndex CEO Jerry Liu認為模型已能自行處理大量非結構化資料,框架需求縮減,語境解析與模組化成為新核心,業界必須調整堆疊策略。同時MCP與ClaudeAgentSkills讓模型即時發現並使用工具,降低整合成本。

深度分析
研究指出,隨著大型語言模型的多代理人系統發展,治理拓撲對集體效能影響巨大。作者將七種歷史政治制度轉譯為可執行的多代理架構,實驗發現同一模型下最佳與最差制度差距超過57%。研究同時提出門檻密度ρ作為衡量治理開銷的指標,說明過高的審核層會導致失敗迴圈。
深度分析
隨著大型語言模型在軟體開發中的應用提升,本文示範如何以純Python建構完整AgenticUI堆疊,透過AG‑UI事件流即時觀測代理行為,並以A2UIJSON宣告式描述介面,讓LLM直接產生互動式UI,最終展現即時同步與安全審批機制。為開發者提供可擴展的Agentic UI藍圖。

desktop-touch-mcp
desktop-touch-mcp是一個為Windows設計的MCP伺服器,透過語意世界圖與自動感知機制取代傳統座標點擊,提供螢幕截圖、鍵鼠與UI自動化等28項高訊號工具,Rust引擎提升近百倍效能,讓LLM代理人以更少代幣完成桌面操作。並支援Chrome遠端除錯與終端指令。

深度分析
隨著AI代理人能操作電腦圖形介面,安全與資安風險同步升級。研究系統化整理CUAs的威脅類型、防禦手段與評測基準,指出視覺誤判與指令注入等漏洞,呼籲建立統一安全標準與透明機制。同時,本文比較傳統RPA與新興CUA在功能與風險上的差異,並預測此技術將重塑開發者生態與法規治理。
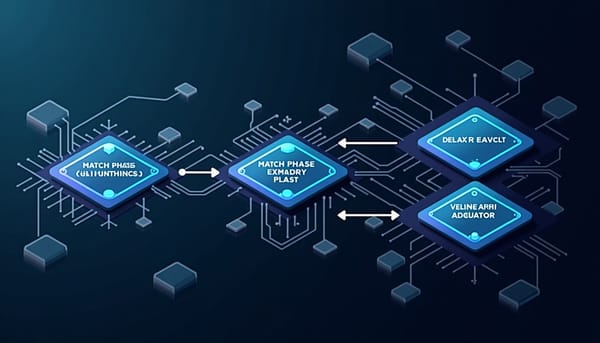
深度分析
MappingEvolve 提出以大型語言模型(LLM)直接演化科技映射(technology mapping)核心演算法,將映射流程抽象為三個可演化操作子:MatchPhase、MatchPhaseExact 與 MatchDropPhase,並以 Planner→Evolver→Evaluator 的分層代理架構執行策略選擇、變異產生。