深度分析
TraceLab:編碼代理工作負載分析與 LLM 服務最佳化策略
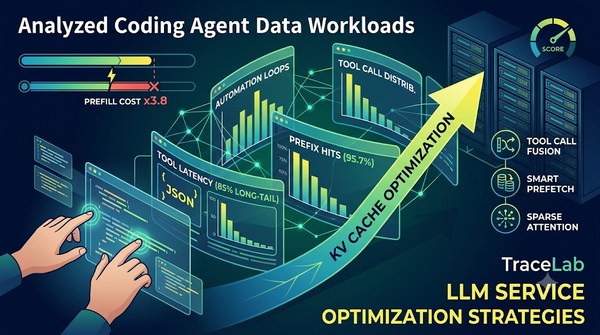
研究針對編碼代理在實務使用中的4,300場會話進行追蹤,發現長自動迴圈、長前綴短輸出、工具呼叫高度分散且快取命中率高。此結果指出降低工具呼叫開銷與改進KV快取管理可提升服務效能。前綴快取全局命中率達95.7%,但在人為間隔較長時仍會失效,導致預填代價提升3.8倍。
深度分析
研究針對編碼代理在實務使用中的4,300場會話進行追蹤,發現長自動迴圈、長前綴短輸出、工具呼叫高度分散且快取命中率高。此結果指出降低工具呼叫開銷與改進KV快取管理可提升服務效能。前綴快取全局命中率達95.7%,但在人為間隔較長時仍會失效,導致預填代價提升3.8倍。

深度分析
研究指出,當大型語言模型的KV快取跨GPU分割時,使用Multi‑headLatentAttention以路由查詢代替搬移快取,可在多節點H100叢集上減少超過70%的傳輸位元,且在小批次查詢下以十微秒等級的延遲取代毫秒級的快取重組。此結果為未來跨實例推論提供實務參考。

速報
最新研究觀察到,讓大型語言模型在同一請求中並行展開多條生成分支能提升潛在吞吐,但既有服務策略要麼貿然放行造成共享解碼步驟延遲膨脹,要麼以固定上限過度保守放棄效能。論文提出 TAPER,一種按步(per-step)的入場控制器,將額外分支視為機會性工作,只有在預測的分支外部性可由當前批次的 slack 預算吸收時才放行。