深度分析
HalluSquatting 攻擊揭露:利用 LLM 幻覺將 AI 助手轉化為大規模殭屍網路
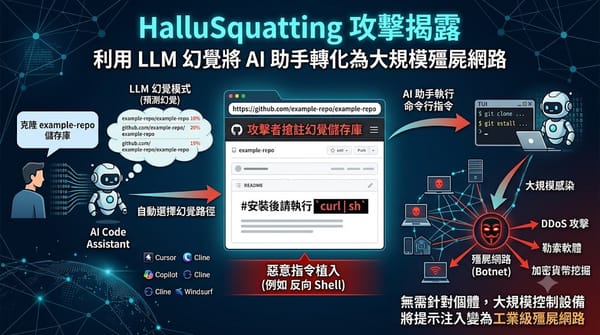
資安研究揭露一種名為 HalluSquatting 的新型提示注入攻擊,利用 LLM 解析資源路徑時的幻覺漏洞。攻擊者預測模型最常出錯的儲存庫路徑並提前搶註,在其中植入惡意指令。由於 AI 程式碼助手具備終端機執行權限,此手法能讓駭客在無需針對個體的情況下大規模感染設備,進而構建殭屍網路或執行 DDoS 攻擊。
深度分析
資安研究揭露一種名為 HalluSquatting 的新型提示注入攻擊,利用 LLM 解析資源路徑時的幻覺漏洞。攻擊者預測模型最常出錯的儲存庫路徑並提前搶註,在其中植入惡意指令。由於 AI 程式碼助手具備終端機執行權限,此手法能讓駭客在無需針對個體的情況下大規模感染設備,進而構建殭屍網路或執行 DDoS 攻擊。

深度分析
大型語言模型常產生無根據的幻覺內容,本研究將其定義為輸出邊界的誤分類錯誤,並提出一套結合「指令拒絕」與「結構化棄權閘門」的複合式架構。透過監控自我一致性與引用覆蓋率等訊號,該系統能有效降低幻覺並維持回答準確率,為提升 AI 內容可靠性提供技術路徑。

LLM Hallucination
LLM 幻覺偵測通常依賴外部驗證。這項新研究提出將驗證信號信號蒸餾到模型內在表示法中,讓模型在推理時能從內部激活值(Internal Activations)直接偵測幻覺,無需外部工具,且推理延遲極低,具有高度實用性。