
深度分析
PalmClaw:將 LLM 代理人完整搬至 Android 手機端的開源框架
隨著大型語言模型代理人從桌面延伸至手機,PalmClaw 以原生手機框架直接管理記憶、工具與執行迴圈,將裝置功能以具結構參數的工具呈現。實驗顯示任務成功率提升約 11.5%,完成時間縮短逾 94%。此設計降低對雲端依賴,提升資安與使用者隱私。同時採用 AGPL 授權,鼓勵社群共同擴充多模態感測與自動化功能。
深度分析
隨著大型語言模型代理人從桌面延伸至手機,PalmClaw 以原生手機框架直接管理記憶、工具與執行迴圈,將裝置功能以具結構參數的工具呈現。實驗顯示任務成功率提升約 11.5%,完成時間縮短逾 94%。此設計降低對雲端依賴,提升資安與使用者隱私。同時採用 AGPL 授權,鼓勵社群共同擴充多模態感測與自動化功能。
速報
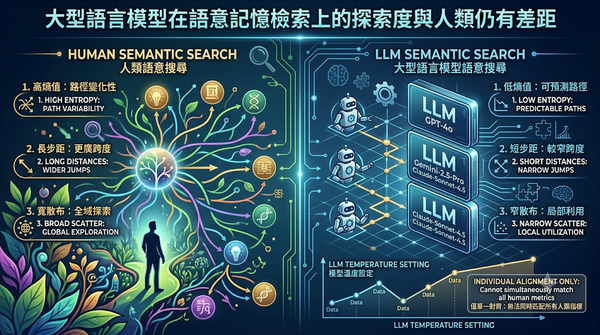
本研究以語意流暢測驗比較人類與三款大型語言模型的搜尋行為,採用熵、步距與中心距三項指標量化。結果發現人類的語意搜尋更具變化與探索性,模型即使調整溫度亦只能在單一指標上對齊,無法同時複製人類的完整特徵,顯示目前模型仍缺乏平衡局部與全域探索的能力。

深度分析
本研究針對 KV 快取壓縮在查詢可見性不同下的表現進行配額匹配審計,發現只有 KeyDiff 在查詢無關情境仍優於三種平凡基線;SnapKV 在加入問題後才顯著提升。結果顯示查詢感知分數掺雜了問題相關性,對部署成本與評估可靠性產生影響。此外,審計揭露注意力後端混淆與基準長度依賴等兩項可重現的評估風險。

深度分析
隨著大型語言模型在前向推理表現卓越,逆向推理能力仍未明朗。研究團隊推出Elenchos框架,透過變形λ演算檢測模型能否辨識與歸因規則變更。結果顯示模型多能偵測異常,卻常無法正確定位變異,顯示抽象因果推理仍是瓶頸。此發現對未來AI安全與可解釋性研究具有重要啟示。
深度分析
多選題評估常因答案長度造成分數偏差,傳統使用未正規化或長度正規化皆有缺陷。研究發現標準分數偏好較短答案,正規化則過度偏好較長答案。本文提出貝式準確度,以答案長度先驗建模消除線性長度影響,無需額外前向傳播,即作即插即用的評估方式。實驗顯示在多項基準與少樣本設定下,偏差明顯降低。

深度分析
本研究提出以原子單元作為智慧壓縮層的理論框架,主張透過可重用的概念性原始結構壓縮資訊。該框架引入壓縮演算,量化表層與原子表示的差異,並提出複合級聯假說,說明抽象層級的壓縮效益會呈乘法增長。實驗顯示,以五欄位原子表示取代自然語句可減少近半的詞彙數,顯示此方法在提升效能與可解釋性上具潛力。

深度分析
研究說明大型語言模型在未使用檢索前對人物或工具的記憶程度,提出NameRank作為辨識分數,透過36模型的開放式提問與人工判斷,僅在回應包含可驗證的非猜測事實時給予正向。結果顯示,具名的實體或方法遠勝於僅有學術或獎項稱號,傳統引用指標無法預測此表現,未來將影響模型評估與資訊檢索策略。
深度分析
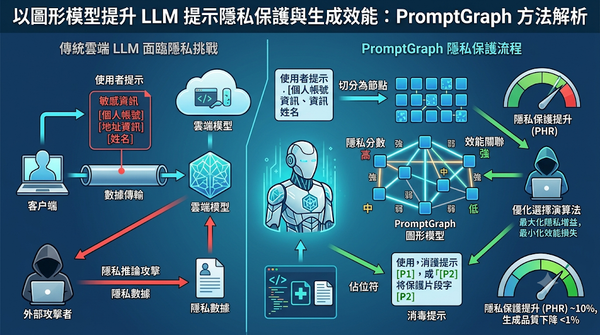
隨著雲端大型語言模型普及,提示資訊暴露隱私風險。研究提出PromptGraph以圖形化方式選取保護片段,同時保留關鍵關聯。實驗顯示在多任務與模型上,可提升隱私防護且維持效能。其將每個提示切分為節點,結合隱私分數與關聯邊權,透過圖形選擇最大化隱私增益並最小化效能損失,較既有方法提升隱私保護率。

深度分析
研究以Anamnesis為平台,結合Anthology與Alterity方法,利用大型語言模型生成具敘事背景的虛擬人格,模擬民意調查。平台支援多模態問卷與人口結構控制,實驗顯示其意見分布較傳統人格提示更貼近真實調查結果。平台支援自訂人口分布與多媒體題型,圖形介面可直接建置與分析問卷。
深度分析
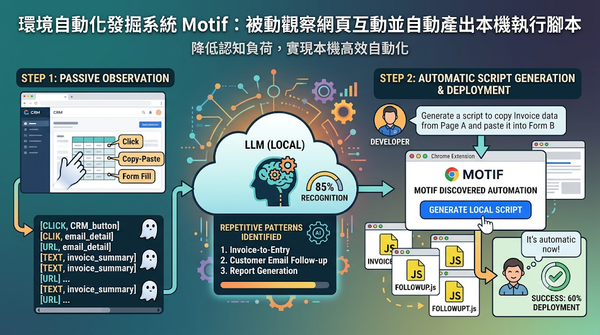
隨著大型語言模型協助程式生成,使用者仍需自行判斷哪些工作可自動化。Motif透過被動觀察瀏覽行為,自動找出重複步驟並建議程式,研究顯示八位參與者中有超過八成的模式被認可,且六成成功部署。這些自動化程式在使用者確認後即可本機執行,降低雲端推論成本,並提供持續可調整的腳本。
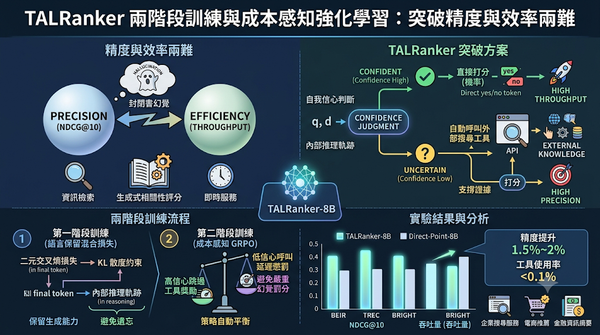
深度分析
隨著使用者需求日益複雜,僅靠參數模型的檢索排序常產生幻覺。TALRanker 以代理式馬可夫決策流程,讓模型在自信時直接打分,不自信時自動呼叫外部搜尋工具。實驗顯示其在多項基準上同時提升精度與吞吐量,此設計亦為企業在即時服務中平衡成本與準確性提供可行參考。
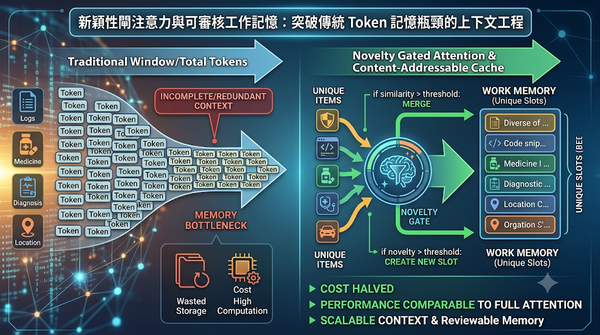
深度分析
研究聚焦於長串冗餘資訊的上下文管理,提出新穎性閘注意力與內容尋址快取相結合的工作記憶。此機制僅保留獨特項目,將記憶規模與資訊多樣性掛鉤。實驗顯示在多領域資料流上,效能媲美全注意力且成本減半,預示未來 AI 系統可更有效率地處理大規模上下文。相較於傳統窗口或重複刪除策略,它在保持關鍵資訊上更具優勢。