
深度分析
LLM 驅動的 OS 調優系統 SemaTune:克服語義盲點提升 Linux 效能
針對作業系統在線調優中缺乏語義理解而導致性能崩潰的問題,研究團隊提出 SemaTune 框架。該技術將 LLM 引入調優迴路,透過快慢路徑雙迴路控制與顯式記憶機制,使系統能理解參數含義並在缺乏應用指標時仍能精準推理。實驗顯示 SemaTune 在 13 種工作負載中性能提升達 153.3%,且能有效避免傳統調優器常陷入的災難性性能下降區域。
深度分析
針對作業系統在線調優中缺乏語義理解而導致性能崩潰的問題,研究團隊提出 SemaTune 框架。該技術將 LLM 引入調優迴路,透過快慢路徑雙迴路控制與顯式記憶機制,使系統能理解參數含義並在缺乏應用指標時仍能精準推理。實驗顯示 SemaTune 在 13 種工作負載中性能提升達 153.3%,且能有效避免傳統調優器常陷入的災難性性能下降區域。
深度分析
隨著大型語言模型被廣泛應用於日常諮詢與道德建議,研究者以 Reddit「Am I the Asshole」的千篇案例,讓 GPT‑4.1、Claude 3.7 Sonnet 與 Gemini 2.0 Flash 以同步與輪流兩種多輪辯論形式共同判定過錯。結果發現,同步模式下 GPT 修正率低於 3%,而 Claude 與 Gemini 超過 28%,且價值取向明顯分歧。辯論格式顯著影響模型的決策慣性與共識形成。

速報
在標記資料稀缺的安全等領域,如何讓大型語言模型在少量樣本下仍具備學習能力是關鍵挑戰。研究提出「注意力頭重新加權 (Attention Head Reweighting, AHR)」方法,只為每個注意力頭學習一個標量,藉此大幅降低需調整的參數量,僅佔模型參數的約 0.0001%。

深度分析
本研究聚焦長上下文大型語言模型的 KV 快取淘汰,指出 H2O 在結構密集的 JSON、XML 等資料中過度保留分隔符與鍵,導致訊號噪聲比惡化。提出基於 SnapKV 的角色條件分配過濾,抑制 KEY 角色提升答案 Token 的保留率,在 5% 預算下恢復超過 60% 的性能缺口,且在較高預算時可匹配或超越完整快取的準確度。
深度分析
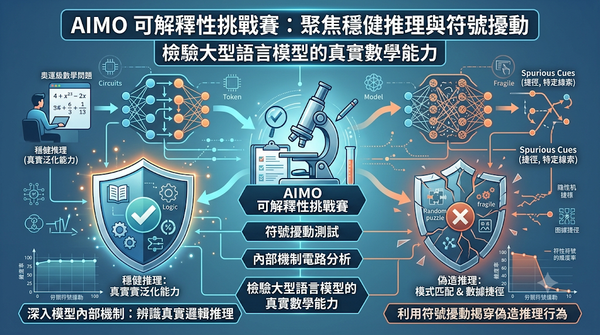
面對大型語言模型在數學基準測試中的高分,研究人員啟動 AIMO 可解釋性挑戰賽,旨在區分真正的邏輯推理與偽造的捷徑。該賽事透過提供奧運級數學問題及其符號表示,要求參賽者分析模型內部機制以辨識穩健推理。初步測試顯示,即使是前沿模型在面對簡單的符號擾動時,正確率也會大幅下降。這將推動 AI 可解釋性研究,確保高風險推理系統的可靠性與泛化能力。
深度分析
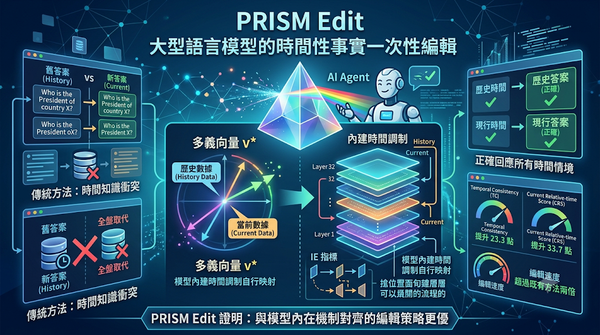
隨著知識持續變動,傳統知識編輯會在時間上產生衝突。研究提出PRISM Edit以單一多義向量結合模型內建時間調制,無需改架構即可同時正確回應現行與歷史時間。實驗顯示在TimeConflict與CounterFact上TC提升23.3點、CRS提升33.7點,且速度超過兩倍。

深度分析
隨著大型語言模型在軟體開發上的突破,硬體設計仍面臨錯誤風險。本研究提出結合形式化方法的逐步細化框架,讓LLM在每一步都受到可驗證規則約束,最終產生正確的RTL程式。實驗顯示此流程在VerilogEval基準上穩定生成符合規範的硬體描述。此技術有望加速晶片設計流程,降低人力成本。

深度分析
隨著大型語言模型部署需求激增,研究團隊提出 dMX 框架,透過可微分的位元寬度參數化在 MXFP 系列間平滑切換,並以溫度退火將學得的連續偏移離散化。實驗顯示在 Llama、Qwen3 與 SmolLM2 上,同時降低平均位元至 5.2 時仍保持或提升準確度,為低精度浮點部署提供更佳效能。

深度分析
隨著大型語言模型讓AI代理人能執行攻擊性安全任務,研究提出以驗證漏洞發現為核心的新評估協議,透過語意匹配與二分圖解決模糊對應,並在多目標多漏洞環境中證實可比傳統CTF基準更具實務參考價值,此協議同時納入效率指標,考量執行時間與成本,提供持續式真實漏洞庫以支援重複與累積評估。

深度分析
隨著城市規劃與流行病學需求大量人類移動模擬,研究提出MobCache框架,利用可重建的潛在空間快取與行動感知解碼器,提高LLM模擬效率且保持多樣性。實驗顯示推論時間降低逾四成、成本下降近五成,品質與最先進方法相當。此技術預計降低城市模擬成本,促進隱私保護下的開放研究。

深度分析
研究重新評估多領域測試時縮放的獎勵模型,發現生成式結果驗證模型在14個領域均表現最佳,挑戰以步驟為單位的精細監督假設,並指出長推理鏈與標籤噪聲是關鍵影響因素,此結果促使未來在法律、醫療等高風險領域的 LLM 部署,更傾向採用生成式結果驗證以提升可信度。

深度分析
隨著大型語言模型可自行使用工具,研究推出DeepTravel框架,利用沙箱與階層獎勵模型訓練自動旅遊規劃代理人,框架採階層獎勵先驗證時空可行性,再以回合檢查細節,並透過失敗回放提升推理,實驗顯示小型模型超越前沿模型,提升行程品質,已於滴滴企業版上線,顯示此技術可加速小模型商業化。