
深度分析
MalEval 框架:以四項任務評測 LLM 在 Android 惡意軟體行為稽核的表現
針對 LLM 在惡意軟體行為稽核上的可靠性問題,研究團隊提出 MalEval 評估框架,聚焦三大痛點:真實標註稀缺、良性程式碼干擾、以及輸出無法追溯與驗證。該框架將稽核流程拆解為函式優先排序、證據歸因、行為綜合與樣本判別四項任務,並搭配人工驗證的資料集與領域專用指標。
深度分析
針對 LLM 在惡意軟體行為稽核上的可靠性問題,研究團隊提出 MalEval 評估框架,聚焦三大痛點:真實標註稀缺、良性程式碼干擾、以及輸出無法追溯與驗證。該框架將稽核流程拆解為函式優先排序、證據歸因、行為綜合與樣本判別四項任務,並搭配人工驗證的資料集與領域專用指標。

深度分析
這篇綜述論文從知識驅動的角度全面回顧檢索增強生成(RAG)的發展。文章首先釐清 RAG 的核心元件:檢索機制、生成流程以及兩者間的知識整合。接著提出一套分類法,從基礎的檢索增強模型到整合多模態資料與推理能力的高階架構。文中也詳述常用評估基準與資料集,並探討問答、摘要、資訊檢索等應用場景。

速報
強化學習(RL)與深度強化學習(DRL)是解決序列決策問題的熱門方法,但模型設計、演算法選擇與超參數調整通常需要專家手動處理,限制了其在組合最佳化等領域的普及。

深度分析
大型語言模型(LLM)在處理最佳化建模時,常因缺乏執行驗證而產生不可執行的程式碼。NEMO 系統以自主編碼代理人(ACA)為核心,在沙盒環境中執行程式碼,確保生成結果可執行並可自動驗證與修復。其非對稱驗證迴圈讓獨立產生的模擬器與最佳化器互相校驗,搭配最小貝氏風險解碼與自一致性機制,顯著提升魯棒性。

深度分析
這篇研究全面回顧了 AI 在學術研究生命週期中的應用,從構想生成、文獻回顧、程式碼與實驗、圖表製作,到論文寫作、同儕審查、答辯與修改,以及成果發表等八個階段。研究發現,AI 在結構化、有明確檢索基礎的工作上表現優異,但對於真正新穎的構想、研究級實驗與科學判斷仍相當脆弱。

深度分析
大型語言模型(LLM)在高風險領域如醫療分診中,常因提示詞過長導致指令遵循能力下降,出現「迷失在訊息中」及上下文視窗溢位等問題。

深度分析
本研究針對企業級 AI 代理人 Leni 的架構進行深入分析,探討其可靠性來源。研究透過 SpreadsheetBench、BullshitBench v2 及 GAIA 驗證集三大公開基準測試,評估驗證迴圈、專業模型與框架對整體表現的貢獻。

深度分析
特徵工程是機器學習的關鍵步驟,但耗費大量人力。研究團隊提出結合大型語言模型與演化演算法的自動化流程,讓 LLaMA 3.1 7B 模型根據既有特徵自動產生新特徵,並以基因演算法篩選。在八個資料集測試中,多數分類準確率獲得提升,且生成的特徵具備可解釋性。
深度分析
主動代理須預測使用者事件並適時協助,但既有評測缺乏此類任務。ProEvent 首創從即時通訊對話中主動維護行事曆的基準,以客觀正確性指標評估。測試八個模型發現,GPT-5.1 也僅在 26.7% 的情境中正確回應,且對事件取消普遍處理不佳,顯示當前 AI 代理仍有根本局限。

深度分析
RAG 系統面臨長上下文處理瓶頸,現有方法缺乏理論基礎。SCP 以合作賽局觀點,用 Shapley 值計算句子邊際貢獻,搭配 3M 參數的 Deep Sets 網路與蒙特卡羅採樣,實現可擴展的上下文排序與剪枝。實驗在多跳推理等任務上表現優異,並提供可解釋性。
深度分析
一項針對4,181道奧數題的研究發現,多智能體系統中專門評審者的錯誤檢測精度雖高(0.861 vs 0.644),但批評被後續答案採納的比例卻遠低於廣播式討論(0.336 vs 0.935),導致最終解題率反而落後。研究指出,評審者精度與批評採納是兩個可獨立測量的維度,設計時須同時關注。
速報
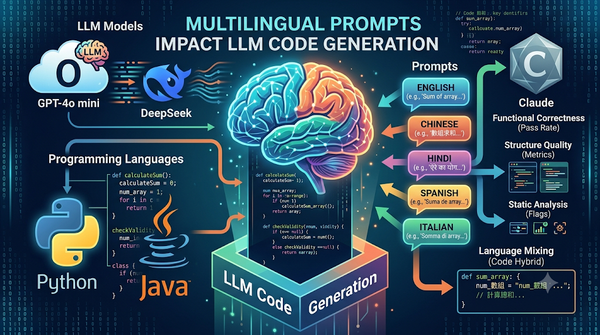
研究探討不同語言提示對大型語言模型程式碼生成的影響,將 460 個 Python 與 Java 任務的英文提示翻譯成四種語言,測試 GPT‑4o mini、DeepSeek、Claude。結果顯示英文提示未必最佳,語言影響視程式語言與模型而定,生成程式碼常混用英語與提示語言。