
深度分析
「Light-MER」輕量化多模態情感語言模型:SWD‑H 隱層對齊與 M‑GRPO 多獎勵優化實證
隨著多模態大型語言模型推動情感辨識與敘事生成,模型規模卻成部署瓶頸。研究提出 Light-MER,利用知識蒸餾、Sliced Wasserstein 隱層對齊與多獎勵 GRPO,將 8B 教師模型能力壓縮至 854M 參數。實驗證明 Light-MER 平均分數超過教師,顯示小模型亦能提供高品質情感理解與生成。
深度分析
隨著多模態大型語言模型推動情感辨識與敘事生成,模型規模卻成部署瓶頸。研究提出 Light-MER,利用知識蒸餾、Sliced Wasserstein 隱層對齊與多獎勵 GRPO,將 8B 教師模型能力壓縮至 854M 參數。實驗證明 Light-MER 平均分數超過教師,顯示小模型亦能提供高品質情感理解與生成。

速報
本研究針對大型語言模型在推理過程中即時更新知識的挑戰,提出一套以敘事背景呈現新資訊、利用自生成多跳問題訓練多步推理、以及透過知識蒸餾讓學生模型內化教師的推理行為的訓練策略。實驗結果顯示,採用此方法的模型能在需要結合多項新事實的複雜問題上顯著提升表現,證明新知的整合不僅是記憶,更是推理過程的一部分。

深度分析
隨著雲端平台功能快速迭代,文件與實際介面常出現落差。AliyunConsoleAgent 透過蒸餾前沿模型軌跡與雙通道獎勵的強化學習,於真實雲端環境中自動驗證文件,達到63.5%成功率,同時將推論成本降低92%。此成果顯示開源模型在企業級雲端自動化驗證上具備可行性,並為降低成本與保護資料隱私提供新路徑。
深度分析
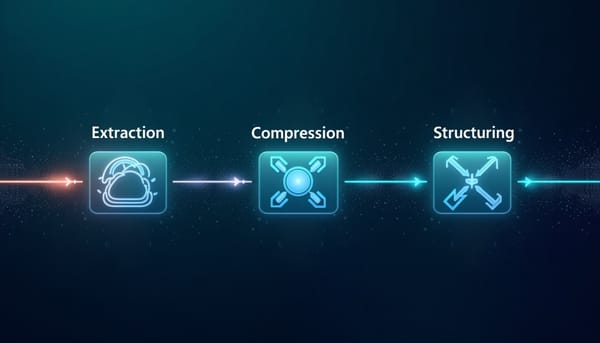
隨著基礎模型規模突破兆參數,傳統的標量蒸餾已無法有效傳遞知識。LoopFM透過將歷史嵌入結構化為VM輸入特徵,開啟高頻寬通道,於公開基準提升AUC超過6%,並在產線將轉換率提升最高1.22%。此框架含抽取、壓縮與結構化三階段,無需即時推論,解決特徵落差與頻寬瓶頸。

深度分析
研究聚焦於高維線性回歸中的知識轉移,透過光譜分析揭示知識蒸餾的光譜視界擴展與弱強泛化的光譜去噪機制,證明轉移效能受隱式正則化與光譜學習速率交互支配,對未來AI模型壓縮與強化學習具重要啟示。此發現亦說明在大模型微調時,教師模型的光譜特性可作為設計新型蒸餾策略的指標。
深度分析
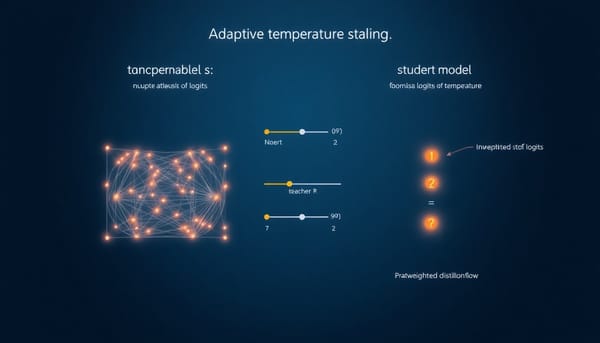
知識蒸餾常以固定溫度 τ 平滑教師預測以揭露「暗知識」,卻忽略樣本間 logit 尺度差異,導致軟標籤熵值高度不一致。CIST(Consistently Informative Soft-label Temperature)提出針對每個樣本的自適應溫度,並對教師與學生採用獨立溫度,同時依教師信心與學生學習難度重新加權蒸餾損失。

深度分析
面對視覺編碼器解凍後感知退化與長期規劃不穩定的挑戰,EvoDriveVLA 提出一套協同感知—規劃蒸餾框架,結合「自錨視覺蒸餾」與「oracle 指導的軌跡蒸餾」。前者透過自錨教師提供視覺錨定約束,並以軌跡導向的注意力加強關鍵區域表徵穩定;

深度分析
科學程式開發常缺乏測試案例,傳統多代理 LLM 框架依賴執行回饋,難以應對此類需求。研究提出 MOSAIC,採用教師‑學生知識蒸餾與結構化問題分解,在不需要 I/O 測試的情況下仍能產出可執行且數值精準的程式碼。

聯邦學習
聯邦學習面臨各端標籤噪聲威脅。本研究提出FedSIR透過類別特徵的頻譜結構辨識乾淨與不良客戶端,並以乾淨端的主向量與殘差子空間做保守重標記,最後結合logit調整損失、知識蒸餾與距離感知聚合穩定訓練。實驗指向FedSIR在多種噪聲與異質性場景下優於現有基準,改善了聯邦學習的抗噪能力。

深度分析
針對自駕車多代理環境的軌跡預測,MAVEN‑T結合教師‑學生框架、混合注意力與多粒度蒸餾,並加入強化學習以突破模仿上限,實驗顯示參數縮減6.2倍、推論提速3.7倍,保持最先進準確度,此成果為資源受限裝置部署提供可行路徑。

窗口注意力
自回歸文字轉語音模型因全域自注意力在長序列上成本高。WAND 透過全局與局部窗口注意力結合,並以課程式學習與知識蒸餾穩定微調。實驗顯示在保持音質的前提下,快取記憶體減少逾 66%,推理延遲幾乎與序列長度無關。
知識蒸餾
為降低大型模型在生產環境的延遲與複雜度,研究者利用知識蒸餾將 12 個教師模型的軟目標作為指導,訓練出更小的學生模型。透過溫度縮放與 KL 散度損失,學生模型在 160 倍壓縮下恢復 53.8% 的精度提升。此方法顯著提升部署效率,對 AI 應用具實質推動力。