深度分析
TISED 框架解析:具身模型推論加速的速度‑品質悖論與硬體影響
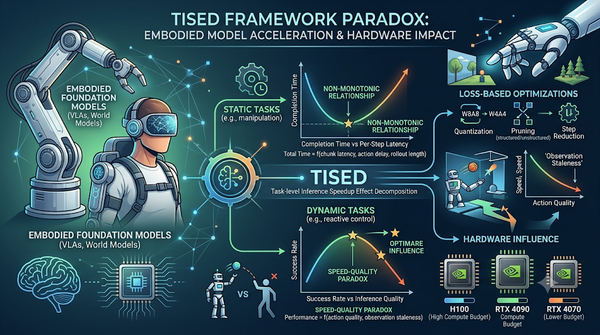
隨著具身基礎模型在機器人任務中的廣泛應用,研究者提出TISED框架統整量化、剪枝等損失式推論優化,解析其對靜態與動態任務的矛盾影響,發現加速每步推論在靜態任務可能延長完成時間,而在動態任務適度削減精度竟能提升成功率,且最佳平衡點會隨硬體配置改變。
深度分析
隨著具身基礎模型在機器人任務中的廣泛應用,研究者提出TISED框架統整量化、剪枝等損失式推論優化,解析其對靜態與動態任務的矛盾影響,發現加速每步推論在靜態任務可能延長完成時間,而在動態任務適度削減精度竟能提升成功率,且最佳平衡點會隨硬體配置改變。

深度分析
大型語言模型推論常受記憶體頻寬與 KV cache 瓶頸影響,Google為Gemma 4推出Multi-Token Prediction (MTP)草擬器,透過輕量草擬器先行預測多個標記,再由目標模型一次驗證並共享激活與快取,達到在不降低輸出品質或推理準確度下大幅提升推論效率,並針對邊緣與加速器提出特定優化。

深度分析
MoE 大型語言模型效能佳但資源消耗高。MoBiE 透過聯合 SVD、全局梯度融合 Hessian 與零空間誤差約束,解決跨專家冗餘與路由偏移問題。實驗顯示在 Qwen3‑30B‑A3B 上 perplexity 降 52.2%,零樣本表現升 43.4%,推論速度提升逾 2 倍。