
深度分析
AnthroDial:基於GRPO的擬人化對話閉環對齊框架
現有 AI 對話系統常因過於禮貌且傾向於總結,導致在私密聊天中顯得生硬且不自然。研究團隊提出 AnthroDial 閉環框架,透過角色卡與場景卡定義運行時,並結合 L0 有效性閘門與十個行為維度建立可執行評估基準。此外,該框架利用 CDT-ZPD 指導的 GRPO 強化學習,針對能力缺陷進行精準對齊。實驗結果顯示,該方法能顯著提升模型在擬人化對話中的一致性與自然度,使其更符合真實人類的社交行為。
深度分析
現有 AI 對話系統常因過於禮貌且傾向於總結,導致在私密聊天中顯得生硬且不自然。研究團隊提出 AnthroDial 閉環框架,透過角色卡與場景卡定義運行時,並結合 L0 有效性閘門與十個行為維度建立可執行評估基準。此外,該框架利用 CDT-ZPD 指導的 GRPO 強化學習,針對能力缺陷進行精準對齊。實驗結果顯示,該方法能顯著提升模型在擬人化對話中的一致性與自然度,使其更符合真實人類的社交行為。

深度分析
大型語言模型在生成 JSON 等結構化數據時常因機率性質而導致格式錯誤,形成結構鴻溝。研究團隊提出 RL-Struct 框架,透過多維度獎勵函數定義結構層級,並利用 GRPO 演算法在無 Critic 網路的情況下進行輕量化強化學習。結果顯示該方法能顯著提升小型模型的結構準確度與有效性,且模型會自發性地先掌握語法再學習語義。
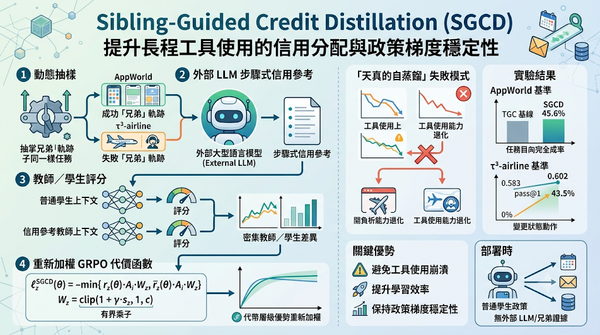
深度分析
研究聚焦長程工具使用強化學習,提出以兄弟樣本引導的信用蒸餾(SGCD)作為信用分配機制,透過動態抽樣與外部語言模型產生步驟式信用參考,重新加權GRPO代價函數。實驗在AppWorld與τ³‑airline基準上分別提升至45.6%與0.602的pass@1,證明SGCD能避免自蒸餾破壞工具使用。

速報
研究團隊針對大型語言模型的推理語言限制,開發了日文推理變體 Qwen‑3‑Swallow‑8B,採用持續預訓練與 GRPO 方法。模型在程式碼、數學與科學基準測試中表現與英語推理基線持平,但在日文文化相關測驗上仍不如既有模型。結果顯示語言控制可行,然而僅靠日文推理並未自動提升文化任務表現,未來仍需針對語言與文化結合進行更深入研究。
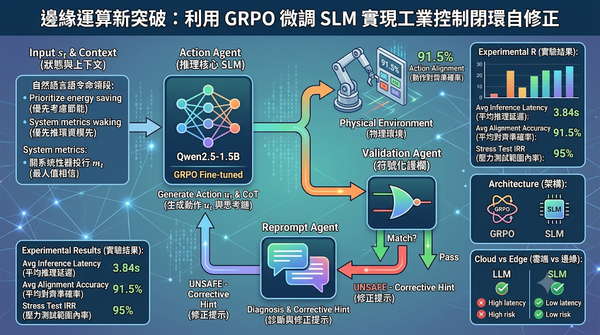
深度分析
工業自動化需將自然語言需求快速轉為控制策略,但雲端大模型延遲高且資安風險大。本研究採用 Qwen2.5-1.5B 小型模型,透過 GRPO 強化邏輯推理並結合符號驗證層與重新提示代理人,建構多代理自修正閉環。實驗顯示其平均動作對齊準確率達 91.5%,且在壓力測試中維持 95% 範圍內率,證明 SLM 方案能有效降低邊緣控制延遲並提升系統可靠性。

深度分析
面對 AI 後訓練技術快速更迭的挑戰,Hugging Face 正式發佈 TRL v1.0 穩定版本。該庫採用混沌適應設計,將穩定 API 與實驗性功能分開,並透過刻意限制抽象化來提高代碼靈活性。TRL 整合了 SFT、DPO 與 GRPO 等超過 75 種後訓練方法,旨在為生產環境提供可靠的基礎設施,並降低開發者在部署高性能 AI 模型時的技術門檻。

深度分析
針對多語言 AI 常以英文思考再翻譯成目標語言的問題,TÜDÜM 專案利用 Qwen3.5-27B 建立土耳其語推理管線。該方案先透過 LoRA 進行監督式微調以強制思考路徑土耳其語化,隨後導入 GRPO 強化學習優化數學表現。實驗發現 SFT 能有效將思考過程轉為土耳其語,雖導致整體準確率下降,但 RL 可部分恢復數學能力。

深度分析
在製造業領域,商業資料常雜訊多、格式不一,導致模型適應困難。研究提出 CLAP閉環訓練‑評估‑釋出流程,將原始資料轉為 SFT、GRPO、評估與門檻資產,並以風險診斷與應用鏈回放決定適配器是否上線。實驗顯示平均分數略升但批次回退仍存,證明僅憑離線分數不足以保證上線效果。
深度分析
本研究探討語言模型在可驗證推理訓練中的核心機制,聚焦於群組相對策略最佳化(GRPO)對標準差的運用,說明其與Dr.GRPO與DAPO的差異,並以數學分析說明樣本數需求與訊號強度,最後預測此技術對AI訓練效率與商業部署的長遠影響。此分析亦比較傳統強化學習獎勵設計,指出GRPO在多樣本不一致時提供更穩定的梯度訊號。

深度分析
材料科學跨領域整合需求提升,傳統大型語言模型缺乏可追溯推理。研究推出Graph‑PRefLexOR,採用圖本位強化學習與群體相對政策最佳化,將推理拆為五階段並生成概念圖。於100題材料與力學問答測試,效能提升40%至65%,推理可追溯性顯著改善,示意圖本位RL可成為科學假說生成的可解釋路徑。

深度分析
本研究探討以較小、領域專精但錯誤的草稿模型,透過不匹配的方式注入強化學習上下文,提升Mathstral-7B在MATH-500與AIME2025/2026的通過率,最終達到71.98%的最高成績,顯示此弱到強激發策略能擴展模型推理能力。此結果挑戰了僅能銳化模型模式的既有觀點。

深度分析
隨著自然語言轉換成優化模型的需求增長,傳統一次性生成方式易因早期符號錯誤導致模型失效。StarOR 以階層式蒙特卡羅樹搜索結合測試時強化學習,於每個非終端節點即時更新LoRA適配器。實驗顯示在五個基準測試上,StarOR 以4B模型取得65%以上的正確率,領先現有大型語言模型。