深度分析
Cerebras 加速 Gemma 4 推論,打造低延遲即時語音 AI 開源模組化管線
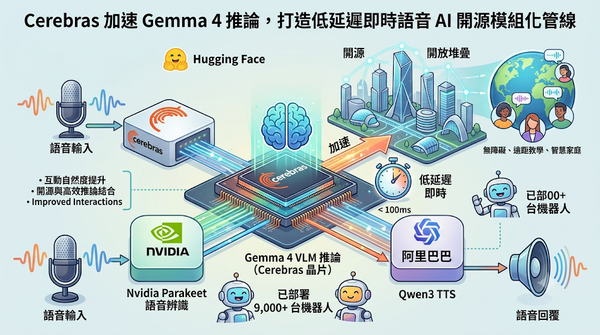
Hugging Face 與 Cerebras 合作,推出以 Gemma 4 為核心的即時語音 AI,採用模組化開放堆疊結合 Nvidia Parakeet、Cerebras 晶片與阿里巴巴 Qwen3 TTS,將回應延遲縮至即時,已於 9,000 多台機器人部署,提升互動自然度並示範開源與高效推論的結合。
深度分析
Hugging Face 與 Cerebras 合作,推出以 Gemma 4 為核心的即時語音 AI,採用模組化開放堆疊結合 Nvidia Parakeet、Cerebras 晶片與阿里巴巴 Qwen3 TTS,將回應延遲縮至即時,已於 9,000 多台機器人部署,提升互動自然度並示範開源與高效推論的結合。

深度分析
HuggingFace讓開源桌面機器人ReachyMini完全本地化對話,採用SileroVAD、Parakeet‑TDT、Gemma4與Qwen3‑TTS四段式串接,避免音訊外流、降低API成本,同時保留模型切換彈性,預示教育與隱私敏感應用的成長潛力。

深度分析
Hugging Face與Cerebras合作推出即時語音AI,結合開源Gemma4 31B與高速推論先進,形成模組化語音到語音流程,將回應延遲縮至即時。此技術已在全球超過9,000多台實際應用於的ReachyMini機器人上部署,提升互動自然度。

深度分析
Gemma 4 為新一代開源多模態語言模型,提供2.3B至31B參數的密集與MoE版本,加入思考模式與統一無編碼器架構,提升推論速度、記憶體與長上下文效能,並採用KV快取共享、p‑RoPE位置編碼與多代幣推測抽稿頭以降低資源需求。實驗顯示在STEM、視訊與長文檔測試上與更大模型相當。

深度分析
Google DeepMind 近期於 Hugging Face 公開 Gemma 4 多模態模型系列,旨在強化裝置端 AI 的推理能力。該系列引入每層嵌入 PLE 與共享 KV 快取技術,並提供五種不同規模的模型以適應各種硬體環境,其中 12B 版本更採用統一編碼器-free 架構以降低延遲。此舉讓開發者能更高效地在本地端部署具備視聽能力的 AI 代理人,推動邊緣 AI 生態的普及。

深度分析
Google 於本週開源 DiffusionGemma,將擴散技術從影像生成延伸至文字生成。模型以 Gemma 4 為骨幹,採 26B MoE 架構,僅激活 3.8B 參數,支援在消費級 GPU 上本地推論。

深度分析
HuggingFace為開源桌面機器人ReachyMini推出全本地化Speech‑to‑Speech解決方案,採用VAD、STT、LLM、TTS四段式串接,讓語音全程在本機運算,提升隱私保護並降低API成本,同時保持多模型切換彈性適用於教育與隱私敏感應用。

深度分析
本文說明在 Chrome Manifest V3 限制下,如何將 Transformers.js 結合 Gemma‑4 模型於背景 Service Worker,並以側邊面板 UI 與內容腳本分工合作,完成本地 AI 對話、工具呼叫與向量嵌入檢索。

深度分析
Google DeepMind 推出的 Gemma 4 12B 為開源多模態模型,採用無編碼器「Unified」架構,支援文字、影像與音訊,能在 16GB 記憶體筆電上本地執行。其 256K 上下文與原生工具呼叫提升企業私密與邊緣運算效能,同時支援原生代理工具與逐步推理模式,降低多模態延遲與 VRAM 需求。

深度分析
研究以 Gemma 4 31B 在 TPU 上完成 LoRA 微調與 vLLM 推理為背景,詳述從 PyTorch→JAX 的改寫、Orbax 到 safetensors 的合併流程,以及在 v6e-8 上部署所需的 Docker 設定。結果顯示 TPU 訓練更快、成本更低,並在長上下文推理延遲與吞吐上展現顯著優勢,惟評估品質部分 GPU 仍有領先。

深度分析
DeepMind於HuggingFace發表Gemma4多模態模型,採Apache2授權便利部署。以分層嵌入、共享KV快取與雙RoPE設計,支援可變影像token與長上下文,含文字、影像與部分音訊輸入。測試顯示多規模在語言與視覺任務上具競爭力,利於本地與邊緣部署。

深度分析
Gemma 4 是 Google DeepMind 在 Hugging Face 上公開的多模態模型系列,採 Apache 2 授權,支援文字、影像與部分音訊輸入,並以本地與邊緣部署為目標。核心設計包含分層嵌入(PLE)、共享 KV 快取與雙 RoPE 配置,視覺編碼支援可變長寬比與多種影像 token 預算,兼顧長上下文與量化效能。