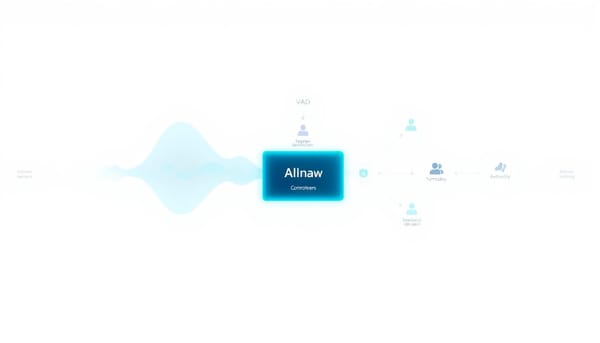
深度分析 UAF 統一音訊前端大模型:一次性整合 VAD、說話者辨識與 ASR 的全雙工語音系統 隨著全雙工語音交互需求提升,研究者提出UAF統一音訊前端大模型,將VAD、說話者辨識、ASR與問答等任務合併為單一序列預測,實驗顯示在延遲與中斷偵測上優於傳統級聯系統,同時支援說話者鎖定與即時問答,顯著降低回應延遲,此設計亦為未來語音助理的模組化與開源生態提供新方向。