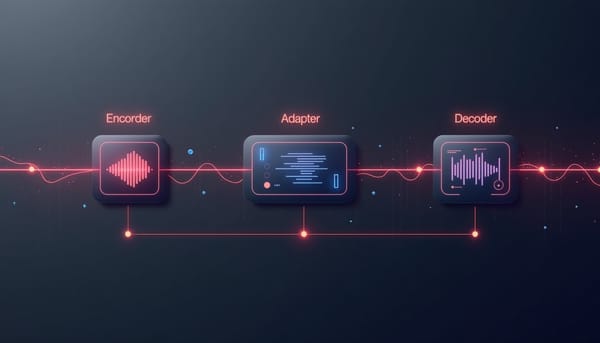
深度分析 MOSS‑Audio 採用編碼器‑適配器‑解碼器架構,實現多模態音訊理解與時間標記 MOSS-Audio旨在打造同時支援語音、環境聲與音樂理解的統一模型,透過DeepStack跨層特徵注入與時間標記,提升多任務表現,於多項基準測試中達到領先成績。模型提供4B與8B兩種規模,分別針對指令執行與深度推理優化,顯示統一音訊模型在未來語音助理的基礎建設上具備可擴展性。