深度分析
SimPref:透過步級偏好學習優化 AI 代理人社交行為
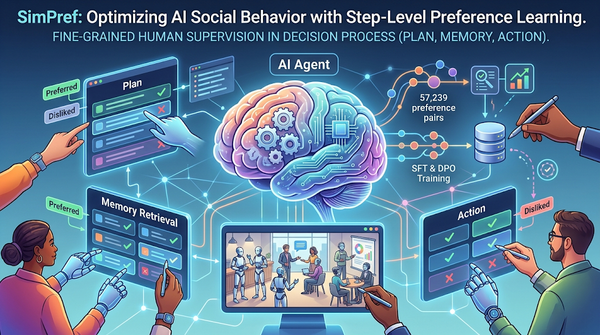
在複雜的社會模擬中,生成式代理人往往缺乏細粒度的行為指導。本研究推出 SimPref 互動介面,讓人類標記員在代理人的規劃、記憶檢索與行動等中間決策步驟中提供即時偏好監督,並建構出包含 5.7 萬組偏好對的資料集。透過 SFT 與 DPO 訓練,開源模型在未知社交情境下的協調能力與行為品質顯著提升,證明步級監督能有效優化長程社交行為。
深度分析
在複雜的社會模擬中,生成式代理人往往缺乏細粒度的行為指導。本研究推出 SimPref 互動介面,讓人類標記員在代理人的規劃、記憶檢索與行動等中間決策步驟中提供即時偏好監督,並建構出包含 5.7 萬組偏好對的資料集。透過 SFT 與 DPO 訓練,開源模型在未知社交情境下的協調能力與行為品質顯著提升,證明步級監督能有效優化長程社交行為。

速報
大型語言模型在複雜推理任務中常面臨對齊挑戰,傳統 DPO 框架因缺乏對多步驟解答的細粒度反饋而受限。研究團隊推出 HiPO 分層偏好優化技術,將回應拆分為查詢澄清、推理步驟與答案區段,並對各段獨立計算損失函數以進行針對性訓練。實驗證明,HiPO 能在維持訓練穩定性的同時,顯著提升 7B 模型在數學基準測試中的表現與邏輯一致性。

深度分析
面對 AI 後訓練技術快速更迭的挑戰,Hugging Face 正式發佈 TRL v1.0 穩定版本。該庫採用混沌適應設計,將穩定 API 與實驗性功能分開,並透過刻意限制抽象化來提高代碼靈活性。TRL 整合了 SFT、DPO 與 GRPO 等超過 75 種後訓練方法,旨在為生產環境提供可靠的基礎設施,並降低開發者在部署高性能 AI 模型時的技術門檻。

深度分析
HuggingFace推出TRLv1.0,從研究原型轉型為可在生產環境使用的穩定庫,內建超過75種後訓練方法,設計兼顧實驗與穩定性,讓開發者快速嘗試新演算法,同時降低部署風險。每月下載量突破300萬,社群貢獻者逾1.7萬人,未來將持續支援非同步GRPO、知識蒸餾與MoE,讓大型模型訓練更具彈性。

深度分析
研究探討把英語上的對比偏好調教延伸到多語環境。CroCo以模型自生成回應配對、用英語訓練的獎勵模型於各語言內排序,並以DPO配對微調與LoRA做參數高效適配。實驗顯示多數語言和任務可見改善,同時減少SFT造成的遺忘。這說明英語訓練的獎勵信號可作為跨語言內部排序依據,降低逐語標註需求。

深度分析
Hugging Face 推出 TRL v1.0,將 75+ 後訓練方法整合於一套庫。採用最小抽象、局部實作的混沌適應設計,提供穩定與實驗雙層合約。此舉提升了在變動 AI 領域的可用性,並預計加速非同步 GRPO 與自動化警示功能的落地,進一步鞏固其在產業環境的影響力。

深度分析
本文針對以偏好學習驅動的大型語言模型對齊方法進行深入分析。

Transformer
SAT為關鍵且具挑戰性的問題。本文提出以transformer為基礎的神經符號後訓練框架,結合MCTS生成偏好資料與教師推理痕跡,採監督微調(SFT)再以直接偏好優化(DPO)精調。最終4B參數模型於100個競賽基準獲得pass@5=53,表現匹敵最佳符號啟發式。
深度分析
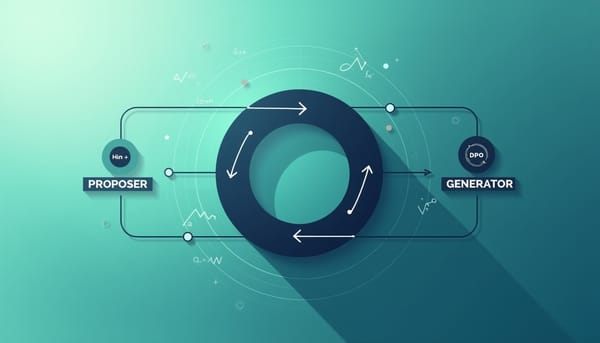
面對開放式、不可驗證任務,G-Zero 以 Hint-δ 建立內生偏好信號,Proposer 生成挑戰題與提示,Generator 以提示引導的回應為學習目標並透過 DPO 更新。實驗顯示在多種模型與評測上觀察到穩定性能提升,代表自我演化可在無外部裁判下前進。

深度分析
本篇教學以輕量模型示範四種後訓練方法:監督微調、獎勵建模、直接偏好優化與群組相對策略,並透過LoRA在ColabT4上完成。結果顯示即使硬體受限,也能提升模型對數學推理與回應品質。同時比較了傳統參數放大與LoRA高效微調的成本差異,指出此路線可降低部署門檻,促進開源社群與企業快速驗證對齊策略。

速報
背景:DPO能學習偏好但難給多步推理段落回饋。方法:HiPO把回應拆成查詢與背景、推理步驟、答案三段,對各段分別計算並加權DPO損失。結果:在Math Stack Exchange偏好資料上微調多款7B模型後,HiPO在數學基準上優於DPO且展現更佳組織與邏輯一致性。

深度分析
TRL v1.0 正式發佈,將原本的研究代碼庫升級為穩定的後訓練庫,支援超過 75 種方法並採用最小抽象設計以因應領域快速變化。新版本在穩定與實驗層面共存,提供明確的合約與升級指引。此舉提升了在產業應用中的可靠性,並預示未來非同步 GRPO 與可觀測性功能的發展方向。