
深度分析
UMEDA:譜門控 Linear Transformer、Diff‑GNO 與子空間差分隱私的多模態圖形聯邦學習
在裝置免穿戴定位場景中,多模態感測帶來異構離散化與分布漂移難題。UMEDA以譜門控線性注意力對齊共享低秩語意,再透過基於核頻譜的擴散圖算子進行生成式聚合,並以子空間投影差分隱私保留主要特徵,顯著改善在異質感測與嚴格隱私下的定位與姿態推估效果。
深度分析
在裝置免穿戴定位場景中,多模態感測帶來異構離散化與分布漂移難題。UMEDA以譜門控線性注意力對齊共享低秩語意,再透過基於核頻譜的擴散圖算子進行生成式聚合,並以子空間投影差分隱私保留主要特徵,顯著改善在異質感測與嚴格隱私下的定位與姿態推估效果。
深度分析
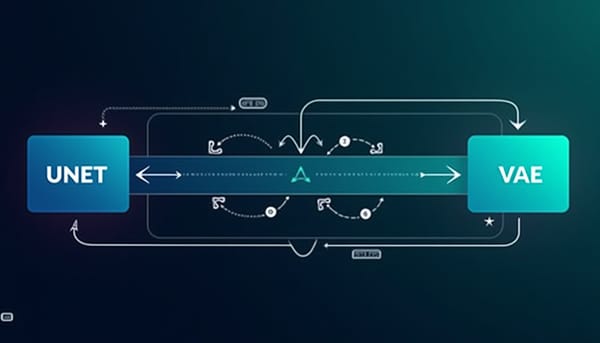
AI生成內容服務快速擴張導致擴充時系統吞吐與單件延遲互相矛盾.SynerDiff提出內外層協同策略:在內部以VAE分塊與自適應Skip-CFG削減VAE頻寬競爭與UNet計算負載;在外部以門檻感知排程規劃併發序列並動態回饋調整吞吐門檻.整體實驗在保持影像品質下,達到吞吐提升1.6×且平均與P99延遲大幅下降。

深度分析
研究指出視覺語言模型可被不改標籤的乾淨標籤後門滲透;作者以擴散模型在語義重要區域生成具觸發特徵的自然中毒影像,並結合多模態引導與GradCAM遮罩強化隱匿性與轉移性;實驗顯示攻擊成功率逾八成且維持原有功能,隱匿性優於既有方法且具跨模型可轉移性

深度分析
在擴散生成模型普遍採樣獨立生成的背景下,研究提出平均場路徑積分擴散(MF-PID),將樣本視為互動代理,用族群密度自洽引導樣本漂移,將分布配適轉為McKean–Vlasov型最適輸運問題。該方法在建築能耗需求響應示例中顯示能量節省並保證終端分布匹配。

深度分析
Sony AI釋出Woosh基礎模型,提供高品質聲音編碼解碼、文字對齊與文字到音訊、影片到音訊四大生成模型,全部開放。與StableAudio-Open、TangoFlux等開源方案比較,Woosh在公共與商用音效資料集上展現更低的Frechet距離,顯示專業音效庫訓練的優勢,預期將促進聲音特效的開放創新。
深度分析
擴散模型因多步去噪而能生成高品質樣本,但採樣步數長、速度慢。本文把路徑蒸餾(trajectory distillation)在線性範疇重寫為算子合併問題:將教師模型每一步視為對含噪資料的投影與縮放算子,學生模型透過合併這些算子以壓縮整個逆向路徑。

深度分析
研究比較近期以GPU為基礎的AI演算法與傳統CPU演算法在最大獨立集(MIS)問題上的表現。作者測試包括基於GFlowNets、擴散模型、非凸優化與強化學習等做法,並以KaMIS與Deg-Greedy為基準進行序列化分析與後處理比較。結果顯示多數AI法仍難優於KaMIS,且部分方法等同或不如最簡單的度數貪婪策略。

深度分析
擴散生成模型訓練耗能巨大,本研究提出在雙線性耦合的熱力學底層上直接應用對稱EquilibriumPropagation作為區域性可讀出的訓練規則。方法證明在零推擾極限下無偏,並給出有限推擾的偏差界與對稱提升至二階偏差的證明。模擬與能耗估算顯示相較GPU有千至萬倍能源優勢。

深度分析
研究在具對稱性任務中提出商空間擴散模型,將等價類視為單一元素以降低學習自由度。作者推導商空間上的擴散過程,並以水平抬升回到原空間實作,保證取樣可回復目標分布。實驗於小分子與蛋白結構生成上,較既有對稱處理與對齊啟發法呈現穩定效能提升。研究結果暗示此方向可簡化模型設計並提升採樣有效性。

擴散模型
面對真實人像影片資料稀缺,研究採用擴散模型結合程式化合成影片進行擴充訓練。方法提供細緻的外觀與動作控制,並在訓練中分析合成與實際資料的互補性。結果顯示適當選取的合成樣本可提升動作真實性與時間一致性。研究為在保護隱私與規模化資料需求下,將合成資料作為可行補助路徑提出實務見解。

深度分析
為突破文字表述的細微差異,研究以文本在擴散模型中所「召喚」的影像分布作為語意相似度衡量;核心做法是比較兩組文本條件下逆時序擴散 SDE 的 Jensen–Shannon 散度並以蒙地卡羅估算;結果顯示其與大型語言模型的 zero-shot 方法相當,且能產生影像層面的可解釋視覺化。

深度分析
為提升迭代精修模型在複雜推理題的學習,研究提出去噪遞迴模型。該方法先以前向腐蝕產生受損目標,再訓練模型於多步遞迴中逐步去噪,介於單步擲回與完整反向訓練之間。實驗顯示在ARC-AGI上優於既有遞迴基線並提升穩定性。同時比較狀態擾動變體SPRM,資料充足時不如DRM;整體提升少量資料下表現。