
深度分析
TS‑LFO 雙階段潛在特徵優化成功繞過擴散模型版權防護
隨著擴散模型客製化應用快速擴散,版權侵害風險隨之上升。研究者觀察到現有的版權防護大多透過在潛在空間加入對抗擾動,破壞影像與潛在表示的對應關係。為此提出兩階段潛在特徵優化(TS‑LFO)方法,先以潛在‑影像對齊損失與時間權重的潛在擴散損失去除高頻擾動,接著利用像素層級約束恢復低頻語意資訊。
深度分析
隨著擴散模型客製化應用快速擴散,版權侵害風險隨之上升。研究者觀察到現有的版權防護大多透過在潛在空間加入對抗擾動,破壞影像與潛在表示的對應關係。為此提出兩階段潛在特徵優化(TS‑LFO)方法,先以潛在‑影像對齊損失與時間權重的潛在擴散損失去除高頻擾動,接著利用像素層級約束恢復低頻語意資訊。

深度分析
隨著文字到影像擴散模型廣受創作使用,缺乏個人化成為瓶頸。研究提出 ZIPP,透過自然語言人格在不需使用者資料或模型調整的情況下,將提示重新寫入人格視角,引導生成符合使用者喜好的影像。實驗顯示在零樣本與少樣本設定下,ZIPP 可提升 13%~20% 的偏好匹配,且保留使用者內部多樣性,降低偏差。

深度分析
隨著工具增多,傳統自回歸規劃易陷入早期承諾限制。DiG-Plan先用擴散模型多樣化提案,再以自回歸精煉依賴,於TaskBench提升約10%ToolF1,實驗顯示擴散提案在Pass@10從0.32提升至0.94,證明其在大規模工具庫下的探索能力。

深度分析
隨著細粒度情感分析需求提升,DiffuSent以非自回歸擴散方式將所有ABSA子任務統一為邊界去噪過程,透過高斯噪聲與對比去噪訓練提升多詞三元組抽取精度,在多樣化語料上測試,實驗顯示在七項子任務上平均F1提升2.48點且推理速度最高可達181倍。

速報
研究者提出「強化隨機流映射」(Strong Stochastic Flow Maps, SSFMs)框架,直接學習加性噪聲隨機微分方程(SDE)的強解映射,將確定性流映射概念延伸至隨機情境。透過多項式近似布朗運動並證明路徑收斂,SSFMs 可在無需模擬的情況下訓練擴散模型的解映射。

速報
研究團隊提出 StressDream,透過優化擴散式影片世界模型的初始噪聲,使想像的未來影像朝向高衝擊但仍合理的結果發展。此方法結合視覺語言模型提供的語意梯度與合理性目標,避免噪聲偏離分佈。實驗以自駕與機械手臂的最先進影片模型驗證,證明可在推論時以文字指定失敗情境,協助更穩健的策略評估與改進,找出可能導致不良結果的動作。

深度分析
自動駕駛在不同城市間轉移時,常被道路拓樸、建築風格與交通型態差異拖垮。此研究提出CityTransfer-Bench作為地理上分離的跨城評測基準,並以CityGen為核心技術:CityGen採用擴散模型(DiT)在HD-map結構條件下,配合目標城市的視覺提示,生成語義一致的多視角城市場景,實現零標註的城市風格適配。

速報
本書系統梳理擴散模型的核心數學與概念,追溯其起源並說明多種表述如何從共通的時間依賴速度場推導而來。作者把生成過程拆解為:前向把資料逐步汙染成噪聲、以及學習反向將噪聲還原回資料的過程,並從變分觀、分數場觀與流模型三方面互補說明。

速報
擴散模型廣泛用於文字轉圖,但概念抹除常只壓制未徹底移除。研究從去噪軌跡發現抹除破壞早期文字對齊但語義仍沿動態傳播,因模型後期仰賴噪聲狀態而出現繞過機會。提出ConceptAgent:免訓練黑盒多代理,透過替代導引噪聲起始喚醒被抹除概念,實驗證實在無參數與梯度存取下仍能準確可控喚醒。

深度分析
文本到影像擴散模型普及後,開放式提示也引發不當生成風險。作者提出推理端的提示投影:用大語言模型產生最小改寫、再以視覺語言模型驗證,選擇性將高風險提示映射到容差控制的安全集合,無需重訓生成器。實驗顯示較模型層對齊能有效降低不當生成率,同時保留良性提示的對齊表現。

深度分析
面對擴散模型在訓練資料中可能帶入的版權與露骨內容風險,本文提出SPACE,一種在交叉注意力權重上以封閉式迭代更新結合L1稀疏化的概念抹除方法,藉由將概念映射集中到低維重要參數子空間來移除目標概念。實驗指出此法在大型模型上改善抹除效能並大幅減少修改後權重的儲存需求。
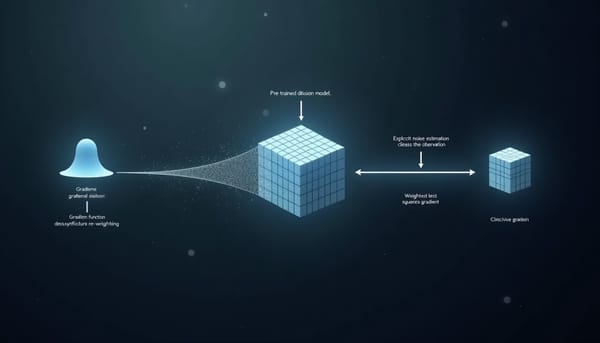
深度分析
研究聚焦以擴散模型處理具離群值的逆問題,論文先以顯式噪聲估計淨化觀測,再以基於Huber損失的逐步重權最小二乘建構魯棒目標,並提出基於梯度下降與共軛梯度的兩種近似求解策略;實驗在多組影像復原任務下顯示出較既有擴散方法更強的抗離群能力。且對噪聲與污染比例具較好適應性。