
深度分析
非因子稀疏編碼與擴散模型:視覺皮層水平連結的計算機制
研究以視覺皮層的水平連結為靈感,提出帶非因子先驗的稀疏編碼模型,利用去噪分數匹配訓練可視為最小化擴散模型。實驗顯示該模型在去噪與輪廓補全上媲美黑盒擴散,同時揭示了連續結構變形的機制。學習得到的交互矩陣與V1表層水平連結相似,並發現大量潛在變量自動脫離視覺輸入,形成全局一致的階層表示。
深度分析
研究以視覺皮層的水平連結為靈感,提出帶非因子先驗的稀疏編碼模型,利用去噪分數匹配訓練可視為最小化擴散模型。實驗顯示該模型在去噪與輪廓補全上媲美黑盒擴散,同時揭示了連續結構變形的機制。學習得到的交互矩陣與V1表層水平連結相似,並發現大量潛在變量自動脫離視覺輸入,形成全局一致的階層表示。
速報
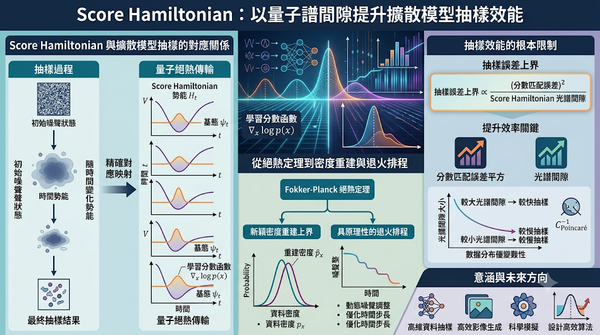
研究顯示分數導向擴散模型抽樣可映射為 Score Hamiltonian 基態的絕熱傳輸。透過時間變化的 Fokker‑Planck 絕熱定理,提出密度重建上界與退火排程。結果指出抽樣上限由分數匹配誤差平方與光譜間隙比值(逆 Poincaré 常數)決定,為抽樣效能提供理論框架。

深度分析
研究針對擴散模型的負向分類自由指導(negative CFG)提出對比式改進(CCFG),利用對比損失在正負概念間拉扯,引導去除不想要的特徵,同時保持樣本品質。實驗顯示在多種條件下均能有效抑制不良概念。此方法亦兼具計算效率,避免大型獎勵模型的訓練成本,為線上個人化生成提供實務可行性。
深度分析
本研究提出視覺分析框架,逐步追蹤擴散模型跨注意力圖,結合熵指標與空間競爭視圖,揭示生成過程階段性變化,示範於 60 組結構化提示,證明可加速人與 AI 的協同探索。透過時間線、相位分段與 token 對比視窗,使用者能快速定位注意力集中與轉移時機,提升對生成影像的解釋能力。

深度分析
擴散模型採樣效率受限於時間步分配的經驗法則。本研究提出 ART 框架,將時間步選擇定義為連續時間控制問題,透過引入採樣時鐘動態調整物理時間推進速度。研究進一步開發 ART-RL,利用強化學習與 Actor-Critic 演算法在高維空間求解最佳採樣率。結果顯示,ART 能在相同計算預算下顯著提升生成品質,且具備強大的跨數據集與跨求解器泛化能力。

深度分析
隨著擴散模型在影像與文字生成上表現卓越,個人化推薦需要即時調整使用者偏好。PAPA 直接以使用者即時回饋優化模型,省去大量獎勵模型訓練,並透過變分推論提升探索效率。實驗顯示於細粒度對齊任務中收斂更快、樣本多樣性更佳,為線上個人化生成提供可行方案。

深度分析
隨著文字生成圖像模型廣泛部署,如何在不重新訓練的情況下刪除特定概念成為關鍵。研究利用稀疏自編碼器偵測目標物件,改以同層特徵取代而非直接在潛在空間干預。實驗顯示,此檢測式取代大幅降低視覺失真,提升概念刪除效果。在UnlearnCanvas測試中平均表現達95.33%,亦在NSFW過濾中展現優勢。

深度分析
傳統擴散逆問題依賴先驗與測量共同推論,然而DAPS++將擴散先驗作為初始化,僅讓測量梯度主導後續優化,實驗在FFHQ與ImageNet上達到與既有方法相當或更佳的重建品質,同時將神經函數評估次數降低約90%。以EM觀點說明先驗在高噪聲下可忽略,顯著提升抽樣速度。

速報
研究提出 CARE(Co-occurring Associated REtained concepts)概念,針對擴散模型的去除(unlearning)任務,避免同時刪除無害的共現概念。作者設計 CARE 分數作為衡量指標,並開發 ReCARE 框架,能自動構建包含目標圖像中良性共現詞彙的 CARE 集,在訓練過程中保護這些概念。
深度分析
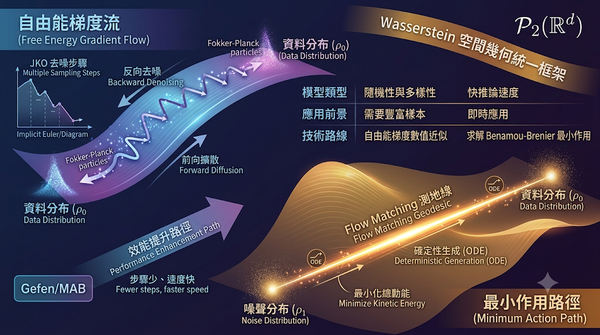
研究以 Wasserstein 空間的幾何為基礎,說明擴散模型的自由能梯度流與 Flow Matching 的最小作用路徑,並比較兩者在生成效率與應用前景的差異。此幾何框架同時揭示了流體力學與李群理論在深度學習訓練中的新角色,並提供未來模型監控與超參數調整的理論依據。

速報
研究分析了 2017 至 2025 年五大 AI 會議(ACL、CVPR、ICLR、ICML、NeurIPS)共 80,814 篇主題論文,發現 AI 研究主題常以階段性相變方式快速崛起。大型語言模型在 2025 年成為跨會議主導議題,擴散模型亦以類似速度興起,語言模型方法透過視覺語言模型滲入電腦視覺領域,而強化學習則呈平緩成長。

深度分析
研究聚焦於神經關係推論中過於簡化的圖先驗問題,提出Diff‑prior以擴散模型校正編碼器的邊緣logits,提升邊緣後驗的決斷性與校準度,實驗顯示結構推論精度明顯提升。同時在多個NRI系列模型上驗證,顯著降低預測不確定性。為未來圖神經網路的可解釋性提供新方向。