
深度分析
子族群層面公平增強演算法與差分隱私效應分析:機器學習模型的隱私風險評估
機器學習在醫療、執法與金融等敏感領域需兼顧效能、公平與隱私。研究改編LikelihoodRatioAttack以子族群審核,揭示不同公平增強方法對成員推論風險的影響,發現隱私風險並非一致上升,且差異受模型結構、子族群大小與差分隱私配置左右。
深度分析
機器學習在醫療、執法與金融等敏感領域需兼顧效能、公平與隱私。研究改編LikelihoodRatioAttack以子族群審核,揭示不同公平增強方法對成員推論風險的影響,發現隱私風險並非一致上升,且差異受模型結構、子族群大小與差分隱私配置左右。
深度分析
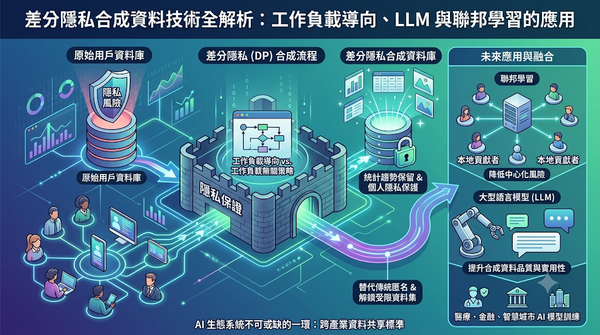
隨著可公開的人類資料日漸枯竭,研究者轉向差分隱私合成資料以保護使用者隱私。差分隱私合成資料在保留原始資料統計趨勢的同時,提供嚴格的個人資訊保護,並可取代傳統的去識別化方法。此技術有望解鎖受限資料集,促進AI模型訓練與商業應用。未來結合聯邦學習與大型語言模型,將提升其實用性。

深度分析
研究指出,解碼式語言模型最後層隱藏狀態可透過梯度最佳化逆向還原文字。作者採用持續於嵌入空間搜尋、最後一次投射的方式,實驗在10字元測試中,精確率從66.9%提升至97.5%。此結果說明,即使僅傳輸浮點向量,也可能被逆向解碼,對分割推論與嵌入API構成潛在威脅。
深度分析
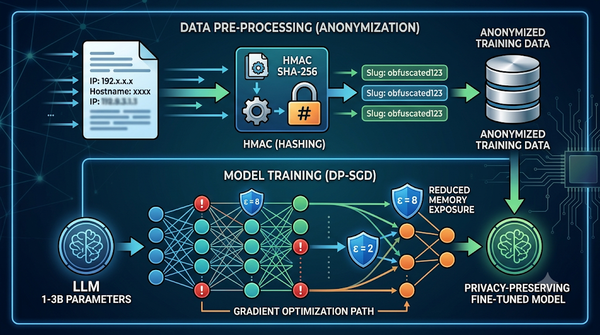
研究聚焦於CSIRT漏洞掃描資料的隱私微調,結合DP‑SGD與HMAC匿名化兩種防護。實驗顯示更新次數主導記憶降低,DP‑SGD只提供額外保證,HMAC可削減40%‑60%曝露且不產生次要目標。此結果提示未來微調需同時考量效能與表示層抹除。

深度分析
研究在公開特徵可得的情況下,提出條件化差分隱私演算法Cond‑DP,透過資料驅動的條件矩陣重塑優化空間,加速私有線性回歸收斂,且不增加隱私開銷,實驗證明在高隱私需求下可顯著提升預測精度,此方法亦支援非線性預測頭,透過Switch‑Cond‑DP先條件化後切換回DPSGD,提升效能。

深度分析
隨著生成式AI與大型語言模型快速普及,合成資料成為隱私保護的替代方案;研究提出一套無需模型存取的稽核框架,透過真實與幻影揭露機制,結合統計假設檢定,提供比以往更嚴謹的隱私泄漏下界。此方法不依賴金絲雀插入或影子模型訓練,顯著降低計算成本,亦可作為會員推斷攻擊的實證下界。

深度分析
隨著AI服務向邊緣移轉,使用者資料分散卻缺乏公平資源分配。研究提出結合差分隱私的多模態語意嵌入與token‑bucket排程,將資料價值以代幣形式衡量。模擬顯示在貢獻不均時仍能維持公平性並提升QoS,同時增強圖像重建防護。同時支援去中心化資料市場的代幣交易。

深度分析
隨著智慧企業需要在保護隱私的同時進行分散式學習,研究提出TITAN‑FedAnil+結合區塊鏈與適應性聚合,以過濾惡意更新並減少記憶體負擔。實驗顯示在8 GB邊緣設備上,記憶體使用降低至81%,且在20輪訓練中保持超過92%的準確度。同時提供區塊鏈共識的狀態簽名機制,確保模型不可篡改。

速報
多代理系統的溝通已受 Agent‑to‑Agent (A2A) 與 Model Context Protocol (MCP) 標準及去中心化身分驗證框架支援,但仍缺乏在組織信任邊界內,能在不解密負載的前提下進行語意路由的機制。

深度分析
面對時序知識圖資料市集的索引老化、估價錯配與差分隱私預算競耗,該系統提出三層架構。第一層用神經ODE衰減捷徑邊並給出召回損失界;第二層以事件條件化估價回應變動;第三層以多臂協調演算法並以高斯機制釋出私有關聯矩陣。實驗顯示召回、延遲與隱私達到競爭性平衡。
深度分析
本研究指出,使用者互動構成的語義相似圖雖能強化跨模態哈希的語義結構,但同時可能洩漏敏感關聯。DMP-MH 採用先裁剪節點度數以限制三角 motif 的 L2 敏感度,再以有噪聲的鏡映沈降合成符合 (ε,δ)-Edge DP 的隱私圖,最後蒸餾到雙流哈希網路,實驗在 MIRFlickr-25K 與 NUS-WIDE 顯示出較佳的隱私-效用與效率。
速報
研究聚焦Kolmogorov–Arnold網路(KANs)訓練理論。作者分析兩層KANs在梯度下降下的動態與泛化,並在NTK可分假設下以logistic損失為例,證明多對數寬度能達到1/T的優化率與1/n的泛化率;在(ε,δ)-差分隱私下效用界為√d/(nε),顯示私有訓練對寬度有更嚴格要求。