
速報
強化學習自動化新突破:AutoRL 讓 AI 不再需要專家手動調參
強化學習(RL)與深度強化學習(DRL)是解決序列決策問題的熱門方法,但模型設計、演算法選擇與超參數調整通常需要專家手動處理,限制了其在組合最佳化等領域的普及。
速報
強化學習(RL)與深度強化學習(DRL)是解決序列決策問題的熱門方法,但模型設計、演算法選擇與超參數調整通常需要專家手動處理,限制了其在組合最佳化等領域的普及。
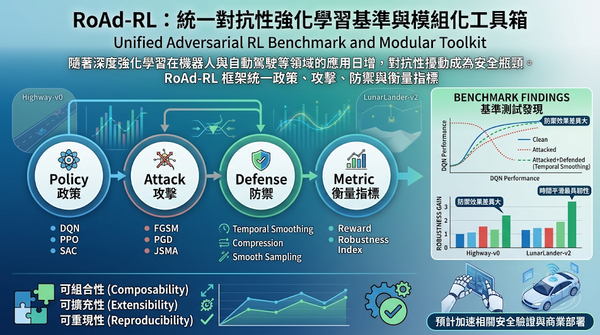
深度分析
隨著深度強化學習在機器人與自動駕駛等領域的應用日增,對抗性擾動成為安全瓶頸。研究者推出 RoAd‑RL 框架,統一政策、攻擊、防禦與衡量指標,並在 LunarLander 與 Highway‑v0 兩大環境測試 192 種組合,發現防禦效果差異大,時間平滑最具韌性。此套件為對抗性強化學習提供可重現基準,預計加速相關安全驗證與商業部署。

深度分析
研究指出持續演員-評價者方法會產生高頻抖動,提出以批評者幾何為核心的PAVE框架,透過混合偏導正則化與曲率保留降低Q梯度波動。實驗在六項MuJoCo與Gymnasium環境驗證,未改動演員即達到與傳統平滑方法相當的平滑度與魯棒性,同時維持任務回報。

深度分析
本研究觀察四名嬰兒在 8 至 30 週的自發運動,發現其末端效應器速度的功率譜密度呈現隨年齡增長的彩色噪聲特徵,指數 β 從約 0.69 上升至 0.88。研究者將此發展規律轉化為一套在深度強化學習訓練過程中逐步提升自相關性的行動噪聲,取代傳統的白噪聲或固定彩色噪聲。

深度分析
研究以自我對弈深度強化學習將LLL格子簡化演算法重新編排,透過AlphaZero式自我對弈與自適應視野MCTS找出更佳操作序列,實驗顯示在未見模數與高維度上零樣本即優於LLL,提升基底品質並減少運算。相較於傳統LLL,Delta‑Star在相同步數減少約40%列操作,展現AI策略的效能提升。

深度分析
安全強化學習常因延遲的拉格朗日更新導致約束違反與震盪。CSPO 引入局部約束敏感度,根據安全邊界的最短有向距離調整修正步伐,加速安全恢復,同時保持原問題的最適解。實驗顯示在導航與機械控制基準上,CSPO 的安全回收速度與獎勵保持度均優於現有方法。

深度分析
本研究以大型語言模型驅動的自我演化科學代理,解決高度非線性流體結構交互的目標導向控制。從單一推進種子策略出發,於第六次迭代即實現全向目標捕捉,最終在第二十次迭代完成可通用、可追溯的控制器,且在未見靜態與動態目標上皆能成功。此外,此流程僅需數十次模擬即完成,遠低於傳統深度強化學習所需的上千次迭代。

速報
本研究針對連續環境的深度強化學習提出新理論框架,將問題建模為連續時間隨機過程,並設計融合探索與隨機轉移的演員-評論家演算法。對單層隱藏層網路證明環境狀態呈雙時間尺度,利用隨機微分方程推導出在極小學習率下的狀態分佈微分方程。實驗以玩具連續控制任務驗證理論,顯示該框架可有效描述過度參數化演員-評論家行為。

深度分析
組合路徑規劃如 TSP、CVRP 受平面對稱影響。MViewRouter 以多視圖交替注意力與集合梯度內化 D4 對稱,讓決策具不變性。實驗證明在標準與實務基準上均達到競爭解品質與零樣本泛化,且較傳統測試時增強更穩定。預期此幾何等變性框架可擴展至 3D 約束路徑與其他車輛調度問題。

深度分析
背景:可調資源控管是雲端部署的重要決策。方法:本文提出RLScale-Bench,統一訓練、架構與評估協議,將六種深度強化學習演算法與經校準的規則式HPA在六種負載與五個隨機種子下比較。結果:發現在成本面HPA普遍最優,惟在突發負載下某些RL可明顯降低SLO違規,凸顯基準校準與報酬工程的重要性。

Soft Actor-Critic (SAC)
在大規模並行模擬背景下,研究比較了PPO與SAC的差距,指出SAC在初期探索、截斷回報處理與獎勵傳播上存在三大問題;透過策略初始化校正、截斷敏感的評論目標與多步回傳估計等修正,實驗在多款腿型機器人任務上顯示SAC可彌補與PPO的性能差距並在部分任務超越。

深度分析
本研究系統評估了塑性介入(如Shrink&Perturb、Weight Clipping、Spectral Normalization、LayerNorm、ReDo和SAM)對深度強化學習(DRL)後門攻擊的影響。