
深度分析
MRSNorm:以相量流形反轉正規化順序,實現梯度均勻化與參數減半
本研究提出 Mean Root Square Normalization (MRSNorm),一種新型正規化方法,旨在解決 RMSNorm 因二次累積變異數導致的數值不穩定性與梯度飢餓問題。
深度分析
本研究提出 Mean Root Square Normalization (MRSNorm),一種新型正規化方法,旨在解決 RMSNorm 因二次累積變異數導致的數值不穩定性與梯度飢餓問題。
深度分析
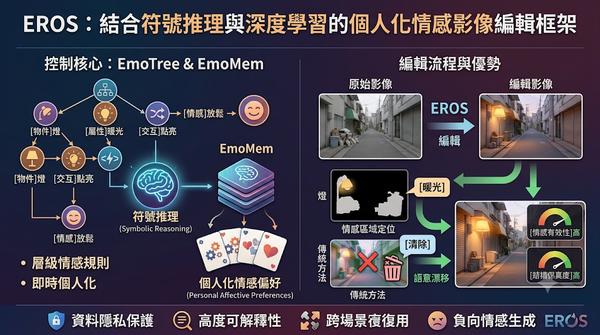
本研究針對個人化情感影像編輯提出EROS系統,結合符號推理與深度學習,透過情感規則樹與可擴充記憶庫在推論時即時個人化。實驗顯示其在引發目標情緒與保持畫面結構上優於現有多模態模型。此技術有望推動情感計算、心理健康與自適應媒體的發展。並具備高度可解釋性與資料隱私保護。
深度分析
本研究回顧1937年Kaczmarz演算法作為最早的隨機梯度下降說明其在解線性方程組時的隨機抽樣機制近期由ChatGPT與Gemini合作證明隨機選擇方程的Kaczmarz最後迭代可在O(1/ε)步內達到任意精度填補了長期理論缺口並為現代SGD收斂分析提供新視角。
速報
本研究針對現有目標偵測模型缺乏顯式記憶機制的問題,提出 Hippocampus‑DETR,將模擬人類海馬體結構的 HipNet 記憶網路模組嵌入 DETR 架構。模型在訓練時採層級優化策略,形成具備記憶檢索與補全功能的子系統,實現特徵的模式分離、模式完成、重要性過濾與資訊整合。
深度分析
研究針對純神經網路能否在無外部符號求解器的情況下學習完整克萊尼三值邏輯,提出模組化架構THEIA,分別以算術、序、集合與命題四個引擎處理,最終在邏輯模組合併。實驗顯示在2M樣本訓練下,THEIA在500步長序列上達到99.97%正確率,收斂速度比同規模Transformer快5.6倍,證明結構化先驗對組合推理的長度泛化至關重要。

深度分析
Moonshine是一個自動化數學研究代理人,核心目標是產生可驗證的數學猜想。它從雅可比猜想抽象核心概念,提出神經雅可比猜想,並在寬度N=n與N=n+1的情況下證明全局單射。它利用結構辨識、橋接建構與障礙辨識三大模組,並保留研究日誌以支援後續驗證。

深度分析
研究檢視層級本地化的Forward‑Forward(FF)訓練,提出DTG‑FF改進方案,於CIFAR‑10/100、ImageNet‑100等九項真實資料集達到SOTA,卻仍比同架構的反向傳播低2‑6個百分點,顯示在高類別與高解析度下的效能天花板。

速報
本研究針對視覺變壓器(ViT)在多物件場景中的特徵綁定問題進行資訊理論化分析,提出測量模型表徵中綁定資訊的探測方法。實驗以不同挑戰(特徵共享、遮擋、自然特徵)之資料集,評估 ViT 各層(CLS token、空間 token)的綁定表現,並比較多個預訓練模型。

速報
儲備運算(Reservoir Computing)在時間序列處理上表現優異,但因必須串行處理與高維儲備的記憶需求,難以大規模應用。

深度分析
現代 AI 模型經歷多階段訓練,導致其最終行為難以溯源。研究團隊提出責任歸屬框架,利用潛在結果形式化定義反事實問題,並透過一階近似估計量量化各階段影響,無需重新訓練即可分析。實驗證明此方法能精準識別導致偽相關或性能下降的訓練階段,為 AI 模型的除錯與審計提供關鍵技術支持。

速報
研究指出當神經網路內部層對連續對稱呈等變時,會出現類Goldstone自由度。作者以理論分析與實驗驗證,顯示這些自由度能跨層維持相干性,並在迴圈迭代中持續傳播資訊,強化表徵多樣性與長期記憶能力。在前饋網路可提升可訓練性與跨層表徵差異性;在迴圈網路則有助於長期資訊保存與序列建模表現。

深度分析
研究針對跨領域的視覺與語言模型,將HarmonicLoss中的歐幾里得距離換成多種非歐幾里得度量,評估其在準確度、可解釋性與碳排放上的表現。結果顯示餘弦距離在視覺任務上兼具精度與低能耗,其他度量則在解釋性上有不同權衡。此結果鼓勵業界探索度量驅動的綠色訓練。