深度分析
Kaczmarz 演算法在隨機抽樣下的最差情況複雜度:AI 主導的完整證明
本研究回顧1937年Kaczmarz演算法作為最早的隨機梯度下降說明其在解線性方程組時的隨機抽樣機制近期由ChatGPT與Gemini合作證明隨機選擇方程的Kaczmarz最後迭代可在O(1/ε)步內達到任意精度填補了長期理論缺口並為現代SGD收斂分析提供新視角。
深度分析
本研究回顧1937年Kaczmarz演算法作為最早的隨機梯度下降說明其在解線性方程組時的隨機抽樣機制近期由ChatGPT與Gemini合作證明隨機選擇方程的Kaczmarz最後迭代可在O(1/ε)步內達到任意精度填補了長期理論缺口並為現代SGD收斂分析提供新視角。
深度分析
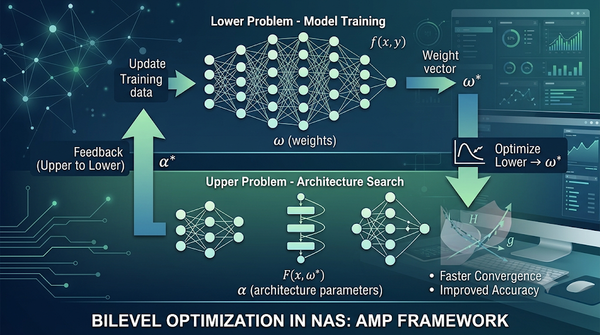
雙層優化已被廣泛應用於機器學習的層級問題。本文將神經架構搜尋視為雙層問題,區分抽樣式與理論導向的搜尋策略,並以輔助數學規劃整合二階資訊,同步更新架構與參數。實驗顯示此類方法在精度與效率上均優於傳統抽樣搜尋,預示未來在自動機器學習領域的廣泛應用。
深度分析
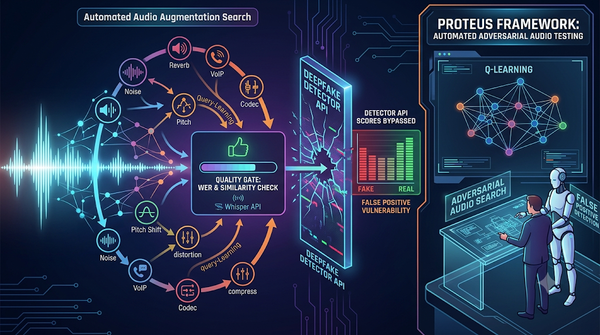
音訊深偽偵測在實務環境常遭編碼、雜訊等處理衝擊。Proteus 以廣度優先與 Q‑learning 兩種搜尋,自動組合 35 種音訊增強,找出在保留可懂度與說話者特徵下欺騙偵測器的鏈結。實驗顯示特定組合可將真聲音分數推向偽造,凸顯偵測系統的假陽性弱點。研究者建議以此結果持續強化模型,並將對抗測試納入開發流程。

深度分析
軟體架構決策涉及複雜的品質權衡與系統約束,傳統 AI 基準測試難以衡量。研究人員推出 SAKE 基準測試,透過 2,154 個專家策劃的選擇題,針對 8 個架構類別與不同上下文長度評估 11 款主流大型語言模型。結果顯示模型整體準確率雖高,但在推理密集型任務中表現不一,揭示了 AI 擔任架構顧問的潛在限制。
深度分析
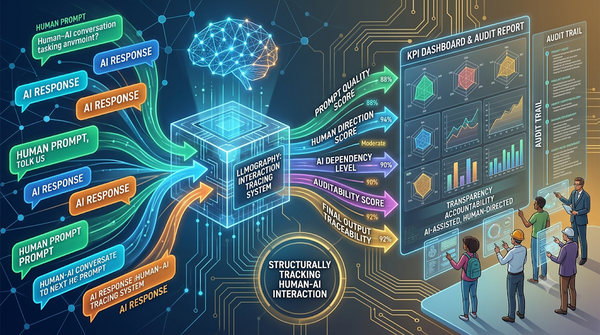
隨著大型語言模型廣泛應用於教育與工程,僅檢測最終產出已不足以評估AI使用情形。LLMography提出將人機對話系統化為可量化指標,涵蓋提示品質、人類指導、AI依賴、可追溯與審計等面向。實驗顯示學生作品多為人機共同創作,提升了透明度與責任追溯。此框架亦可套用於企業內部審計與開源軟體貢獻追蹤,未來有望成為AI透明度的標準化元件。
深度分析
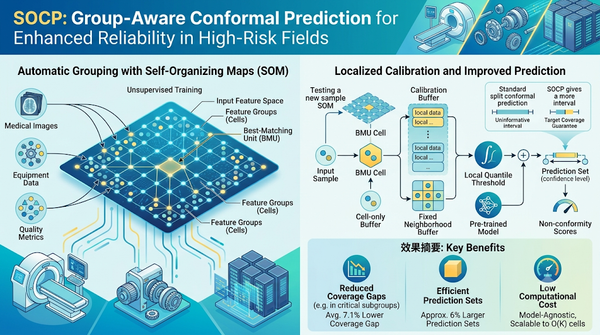
在安全關鍵子群中,傳統保守預測會隱藏區域性不足。自組織保守預測利用自組織映射自動發現輸入空間群組,於測試時從最佳匹配單元或固定鄰域抽取局部校正緩衝。實驗顯示在七項八個基準上降低平均7.1%覆蓋差距,僅增加約6%預測集合大小。此方法不改變預測模型或非符合度分數,兼容回歸與分類,計算成本與K近鄰相當。
深度分析
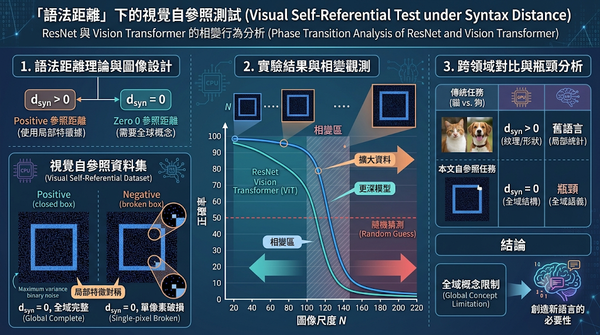
本研究探討視覺模型在缺乏局部特徵線索時的辨識能力,透過語法距離概念構建閉合方框與單像素破損方框的自參照圖像。實驗顯示,隨著圖像尺度超過臨界點,ResNet與ViT的正確率跌至隨機猜測,僅靠擴大資料或模型規模無法突破此上限。此結果揭示現有架構在全域概念任務上的結構性限制。
深度分析
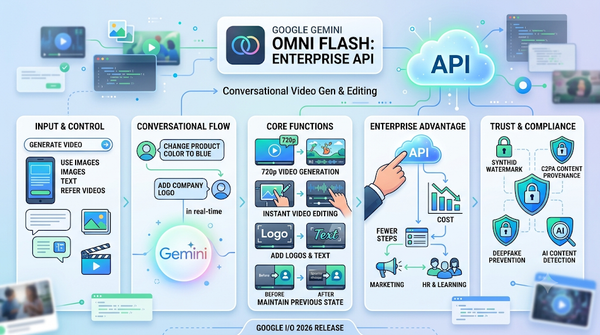
Google在I/O2026推出GeminiOmniFlash,透過API讓企業以對話方式產生與編輯720p影片。模型支援文字、影像與影片參考,並可即時調整畫面、文字與標誌。此功能降低製作成本,同時引發對工作取代與解析度限制的討論,以及資料治理與合規考量。

深度分析
Anthropic於2026年推出ClaudeSonnet5,提供接近旗艦Opus效能的中階模型,價格遠低於高階方案,強化代理式AI完成度與安全性,同時在IPO前提升企業採用與營收預期。新模型使用更新分詞器,可能使 token 數增至 1.0‑1.35 倍,企業需自行測試成本;安全性較前代降低幻覺與順從度。
深度分析
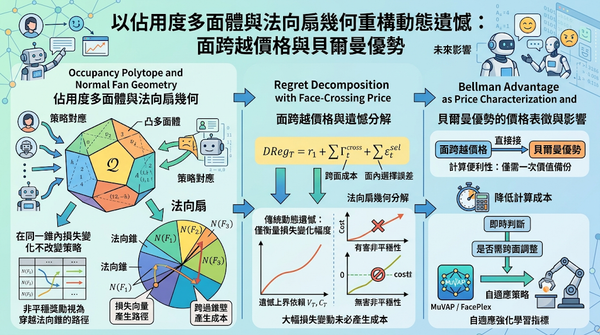
在變動決策問題中,傳統動態遺憾僅衡量損失變化幅度,忽視策略影響。本文以佔用度多面體的法向扇幾何,將非平穩獎勵視為穿越法向錐的路徑,定義面跨越價格,將遺憾分解為跨面成本與面內選擇誤差,僅需一次價值備份即可計算,顯示大幅損失變動未必產生成本,為未來強化學習演算法設計提供新指引。
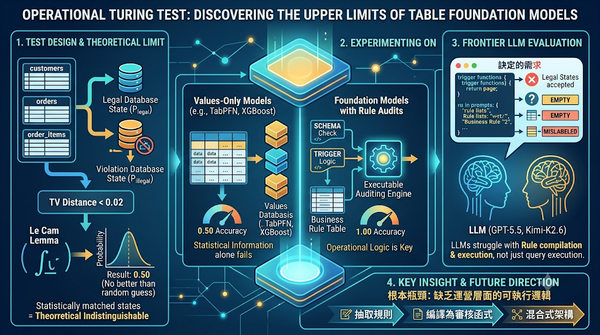
深度分析
本研究提出運營圖靈測試,以統計匹配的合法與違規資料庫狀態檢驗表格基礎模型,發現僅憑值分布的模型無法超過隨機猜測,即使提供行級存取亦無效;加入可執行的規則審核可達100%正確率;而大型語言模型即便在提示中給予完整規則,亦只能辨識不到兩筆合法狀態,顯示缺乏運營層面的可執行邏輯是根本瓶頸。
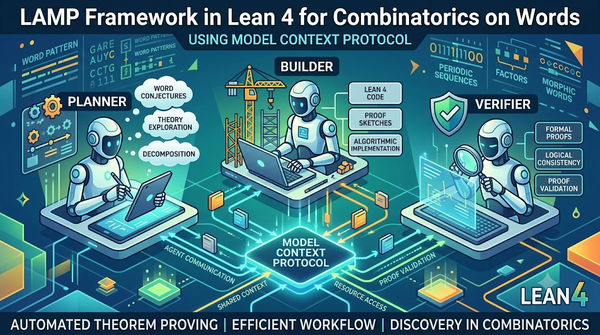
深度分析
大型語言模型在數學推理上進步,但 Lean 4 受限於 Mathlib 領域。LAMP 框架利用 MCP 即時接入詞組合學 (CoW) 本體知識,透過 Planner、Builder、Verifier 產生核查過的證明。實驗顯示在 90 項 CoW 定理測試中,LAMP 驗證率 96.7%,遠超未加工具基線與現有專門化證明器。