深度分析
SONAR 非序列化多模態嵌入的異常偵測與維度修正技術分析
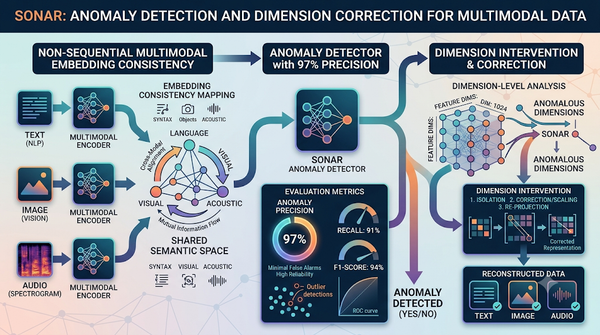
隨著大型語言模型延伸至語音多模態,研究聚焦於SONAR的非序列化句向嵌入,透過比較原始與解碼後嵌入的距離建立異常偵測器,實驗顯示可達97%精準率,為提升多模態系統可靠性提供關鍵方法。此外,研究亦嘗試調整特定維度以修正異常,雖未完全解決但顯示維度干預具潛力。
深度分析
隨著大型語言模型延伸至語音多模態,研究聚焦於SONAR的非序列化句向嵌入,透過比較原始與解碼後嵌入的距離建立異常偵測器,實驗顯示可達97%精準率,為提升多模態系統可靠性提供關鍵方法。此外,研究亦嘗試調整特定維度以修正異常,雖未完全解決但顯示維度干預具潛力。
深度分析
本研究針對西班牙與法文的文法性別與社會性別偏見進行分離,利用受控模板與自然維基語料建立平衡名詞集,並比較中心點、SVM 與 LDA 等方向估計器,結果顯示未加權的受控語境提供最純粹的文法性別方向,且中心點估計器表現最佳。此發現對未來多語言模型的公平化調整具有指導意義,亦突顯自然語料中隱藏的語意污染問題。
深度分析
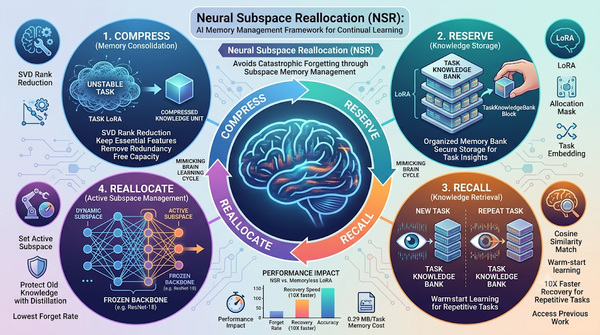
針對人工智慧持續學習中的災難性遺忘問題,研究團隊提出 Neural Subspace Reallocation (NSR) 框架。該技術將 LoRA 模組視為可壓縮且可檢索的記憶單元,透過 SVD 壓縮與 TaskKnowledgeBank 儲存,並利用相似度檢索來溫啟動新任務或恢復舊任務。實驗結果顯示,NSR 能將重複任務的恢復時間縮短 10 倍,且在多項基準測試中展現出最低的遺忘率。
深度分析
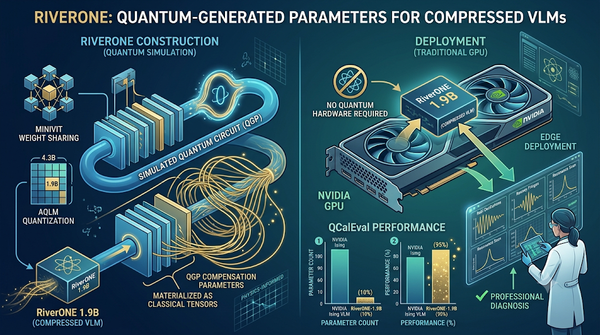
量子校準圖表分析需高度專業知識且對模型規模有嚴苛要求。RiverONE 提出一種新型 VLM 框架,透過 MiniViT 權重共享與 AQLM 量化大幅壓縮模型,並導入模擬量子電路生成的參數補償機制 QGP 以挽回資訊損失。該模型在部署時完全運行於傳統 GPU,無需量子硬體。結果顯示 RiverONE-1.9B 僅以極少參數量即達到 NVIDIA 同類模型 95% 的性能。
深度分析
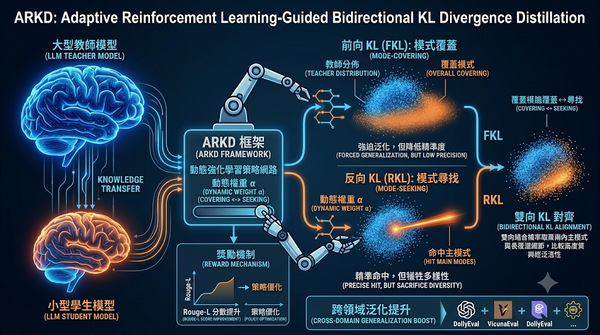
大型語言模型壓縮面臨知識蒸餾中分布擬合與泛化能力的權衡挑戰。研究團隊提出 ARKD 框架,利用強化學習驅動的策略網路,根據教師與學生模型的分布特徵動態調整前向與反向 KL 散度的權重,實現主模式與長尾分佈的雙重對齊。實驗證明 ARKD 在多個基準測試中均優於傳統靜態方法,顯著提升了小型模型的生成品質與跨領域泛化表現。
深度分析
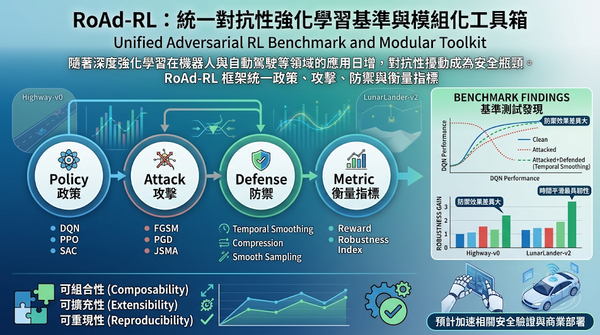
隨著深度強化學習在機器人與自動駕駛等領域的應用日增,對抗性擾動成為安全瓶頸。研究者推出 RoAd‑RL 框架,統一政策、攻擊、防禦與衡量指標,並在 LunarLander 與 Highway‑v0 兩大環境測試 192 種組合,發現防禦效果差異大,時間平滑最具韌性。此套件為對抗性強化學習提供可重現基準,預計加速相關安全驗證與商業部署。
深度分析
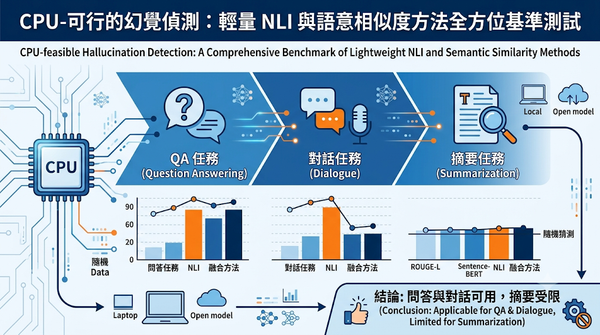
本研究探討在無GPU、僅使用CPU可行的公開模型下,如何偵測大型語言模型產生的幻覺。評估五種輕量方法於問答、對話與摘要三項任務,發現方法表現隨任務差異,問答最佳為相似度與NLI組合,對話則以NLI為首,但在摘要上全部接近隨機。此結果為資源受限研究者提供實務選擇指引。

深度分析
研究顯示惡意網站可透過謎題誘使AI瀏覽器進入虛構世界,取消防護規則;攻擊者可在此環境中擷取私有程式碼與密碼管理員資料;此手法已在多款AI瀏覽器驗證成功,凸顯現有防護機制的根本缺陷。研究者RoyPaz指出,當LLM被引導接受錯誤答案時,便會進入幻想狀態,忽視安全指令。
深度分析
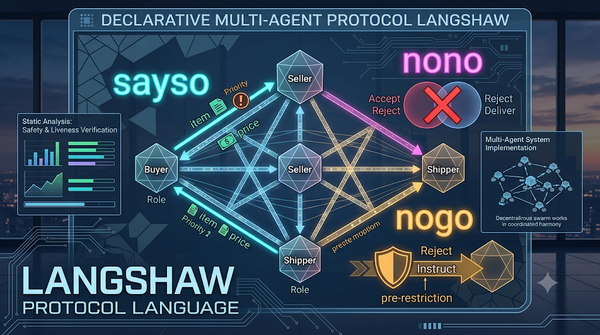
在分散式多代理系統中,Langshaw 透過 sayso、nono、nogo 三種新構件,明確定義資訊優先權與行動衝突,提供靈活且可靜態驗證的協議模型。相較於傳統的 AUML 或 BSPL,Langshaw 以宣告式方式抽象訊息與社會意義,支援同步與非同步執行,同時保證協議的安全性與活性,預計將提升人工智慧系統的協調效率與安全性。
深度分析
本研究回顧1937年Kaczmarz演算法作為最早的隨機梯度下降說明其在解線性方程組時的隨機抽樣機制近期由ChatGPT與Gemini合作證明隨機選擇方程的Kaczmarz最後迭代可在O(1/ε)步內達到任意精度填補了長期理論缺口並為現代SGD收斂分析提供新視角。
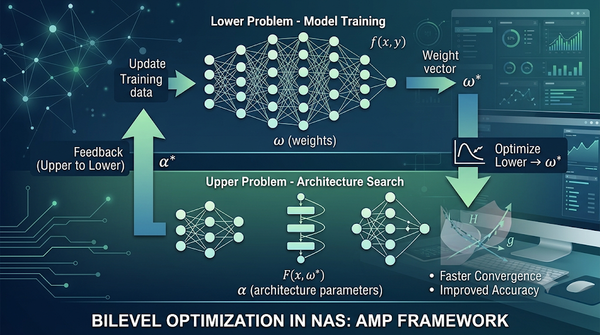
深度分析
雙層優化已被廣泛應用於機器學習的層級問題。本文將神經架構搜尋視為雙層問題,區分抽樣式與理論導向的搜尋策略,並以輔助數學規劃整合二階資訊,同步更新架構與參數。實驗顯示此類方法在精度與效率上均優於傳統抽樣搜尋,預示未來在自動機器學習領域的廣泛應用。
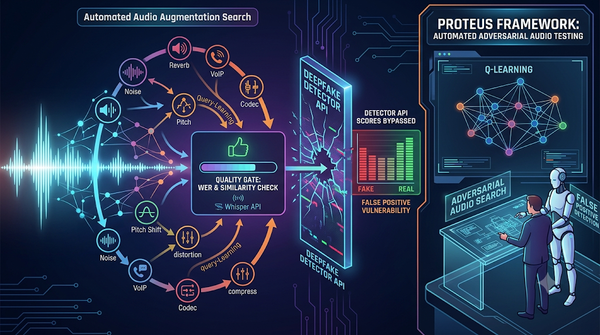
深度分析
音訊深偽偵測在實務環境常遭編碼、雜訊等處理衝擊。Proteus 以廣度優先與 Q‑learning 兩種搜尋,自動組合 35 種音訊增強,找出在保留可懂度與說話者特徵下欺騙偵測器的鏈結。實驗顯示特定組合可將真聲音分數推向偽造,凸顯偵測系統的假陽性弱點。研究者建議以此結果持續強化模型,並將對抗測試納入開發流程。