
深度分析
拓樸空洞(TVA)框架:利用向量嵌入與 SLERP 自動發掘技術缺口
本研究針對軟體與硬體技術文件建構高維嵌入空間,提出拓樸空洞(TVA)框架以自動發掘未被覆蓋的概念三元組,並透過球面線性內插檢驗中點是否被占用。實驗顯示在Linux核心與x86特性上,TVA可在數十億候選中篩選出少數具創新潛力的空洞,顯著降低人工探索成本。
深度分析
本研究針對軟體與硬體技術文件建構高維嵌入空間,提出拓樸空洞(TVA)框架以自動發掘未被覆蓋的概念三元組,並透過球面線性內插檢驗中點是否被占用。實驗顯示在Linux核心與x86特性上,TVA可在數十億候選中篩選出少數具創新潛力的空洞,顯著降低人工探索成本。

深度分析
隨著多代理 LLM 在軟體開發中同時產生寫入意圖,AI‑Atomic‑Framework (ATM) 提出以原子與 CID 仲介者進行平行、序列或失敗封鎖的預寫入治理,實驗涵蓋 12 種情境、三個實際案例與 20 個測試,證實 ATM 能在不取代 Git 合併的前提下,提供可審計的寫入前審批機制。

深度分析
隨著大型語言模型在自動程式撰寫中的應用,資訊檢索成關鍵瓶頸。Libra透過可變的Markdown目錄,結合Prompt、Solver、Healer三個凍結LLM形成對抗式優化迴路,使索引自動調整。實驗顯示在SWE‑benchLite多個倉庫中,代碼定位精度持續以對數幅度提升,且可跨模型零樣本遷移。

深度分析
隨著檢索增強生成被廣泛應用,文字中毒攻擊成為安全盲點。研究提出PRA‑RAG演算法,利用多組檢索組合與最小半徑球選擇穩健子集,將攻擊成功率壓至1%,同時保持71%準確度。此外,作者給出語義偏移上限的理論證明,將最大偏移限制在2R以內,為RAG系統提供可量化的安全指標。

深度分析
個人知識圖譜提供隱私友善的偏好建模方式,但從分散式對話資料建構仍具挑戰。本研究提出以輕量大型語言模型抽取RDF三元組,並以Wikidata識別碼對齊,形成可互操作的PKG。實驗顯示,部分模型在抽取精度與下游推薦效能上具比例性優勢。評估使用ReDial對話資料集,Gemma-12B Instruct在精度與召回上領先。

深度分析
隨著計算資源指數成長,研究探討不同AI性能指標對模型差距的影響。若以有界指標衡量,低成本模型最終可趕上前沿模型;若以無界指標,能力將集中於少數巨頭。結果暗示政策與產業格局將因指標選擇而大相逕庭。此外,研究亦比較了AIIQ與VibeThinker‑3B等模型評估方式,指出指標設計會影響開發者生態與商業投資策略。
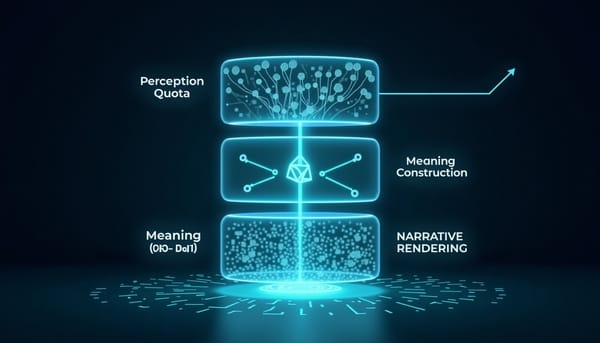
深度分析
研究提出Loom框架以三層管線分離敘事事件與感官描寫,透過感知配額層、意義建構層與敘事渲染層控制描述密度,實驗顯示在保持事實完整的同時提升文句感染力。該系統在ROCStories測試集上超越多項最先進基線,且在人類盲測中獲得更高的敘事忠實度與表現力評分,顯示可控渲染有望成為創意寫作的新標準。

深度分析
隨著AI代理人能自動化軟體操作,研究團隊推出DigitalCoach多模態資料集,收錄72場專家對新手的GUI教學對話,並以此評估先進模型的教學表現。結果顯示模型偏好直接指令,在真實互動測試中缺乏解釋與視覺根據,導致學習者參與度與技能保留皆較差。

深度分析
研究背景:人工智慧回應可信度成關鍵。核心技術:Theoria將答案重寫為帶類型證明步驟的狀態序列,並以完整變更不變式檢測隱藏前提與偽造引用。主要結果:在HLE‑Verified Gold測試中達到91.4%嚴格精準率,且對抗性測試比傳統LLM評分提升近12個百分點。

深度分析
DiffusionTransformer在1K解析度表現優異,推向原生4K多樣長寬比卻遇位置編碼、VAE壓縮與優化耦合問題。UltraFlux採用Resonance2DRoPE+YaRN、非對抗VAE後訓練、SNR感知Huber小波損失與階段式美學課程,於基準測試中超越開源模型,AUC提升逾6%。

深度分析
隨著大型語言模型逐漸接入科學軟體,如何判斷工具使用是否提升計算可靠性成為關鍵。研究推出PHREEQC-MCQ-200基準,要求模型自行產生PHREEQC輸入、執行模擬並從結構化輸出中取得答案。結果顯示,工具增強能顯著提升整體正確率,但亦會導致部分已正確的題目失分,顯示效能並非單調提升。

深度分析
材料科學跨領域整合需求提升,傳統大型語言模型缺乏可追溯推理。研究推出Graph‑PRefLexOR,採用圖本位強化學習與群體相對政策最佳化,將推理拆為五階段並生成概念圖。於100題材料與力學問答測試,效能提升40%至65%,推理可追溯性顯著改善,示意圖本位RL可成為科學假說生成的可解釋路徑。