
深度分析
利用 TRACE 評估 LLM 教學助理在答案鍵情境下的推理提前性
本研究針對大型語言模型教學助理探討答案驅動推理問題,提出TRACE截斷式思考鏈審計方法,以不同答案鍵情境測試1000題GSM8K。結果顯示,提供正確答案鍵可使金標答案在前10%推理前綴即被回收,AUC從0.375提升至0.900。此技術為教育AI的過程層面可靠性提供輕量化診斷。
深度分析
本研究針對大型語言模型教學助理探討答案驅動推理問題,提出TRACE截斷式思考鏈審計方法,以不同答案鍵情境測試1000題GSM8K。結果顯示,提供正確答案鍵可使金標答案在前10%推理前綴即被回收,AUC從0.375提升至0.900。此技術為教育AI的過程層面可靠性提供輕量化診斷。

深度分析
隨著大型語言模型在科研構思上的應用日益成熟,ResearchStudio‑Idea 以 Paper‑Search、Scoop‑Check 與 IdeaSpark 三項開源技能,提供文獻根據、先驗衝突檢查與端到端構思流程,助研究者在實驗前產出具證據基礎的創新方向。該套件在 ICLR、ICML、NeurIPS 等頂會抽取 1,947 篇成果,形成 15 種可重用的構思模式,並顯示口頭發表與高被引間的顯著差異,為未來 AI 研究提供量化指引。

深度分析
隨著大型語言模型向自律代理轉型,可靠性與安全性成為瓶頸。研究將基因調控網路的五大控制動機映射為軟體設計模式,提供噪聲抑制、分層防護、資源治理等機制,實驗顯示可降低幻覺與循環錯誤,預示未來AI系統將更具結構化安全與可擴展性。並促進跨領域的模型治理與開源工具整合。

深度分析
大型語言模型安全性需求提升,研究提出MAG框架在每筆輸入前加固定指令,利用激活幾何差異抽取推理特徵,證實可預測模型判斷並以單向量操控決策,提升資料選擇精度至94.7%Top‑1。MAG可比較八種操作子,發現部分特徵線性表徵強,適用向量導向調整模型行為;在選擇訓練資料時,RFD相似度超傳統激活相似度。

深度分析
終身學習 AI 代理人常面臨語義記憶與運行時快取不同步導致的資訊過時問題。PlaceMem 提出記憶膠囊機制,將語義內容與 KV 快取等運算產物綁定在單一版本化識別碼下,並建立控制平面來管理複用與失效。實驗證明該方案能顯著降低首個 Token 延遲,同時在記憶修正後完全消除過時資訊的命中率,為高效能且可靠的長程記憶系統提供新路徑。
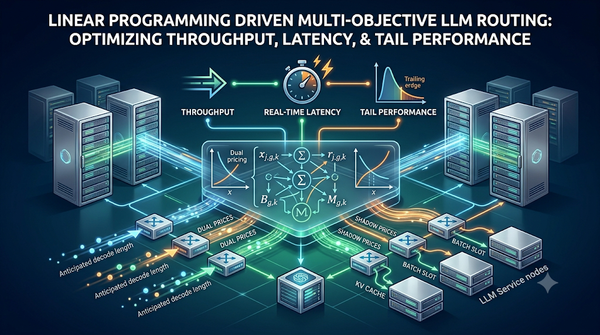
深度分析
隨著 LLM 服務需求激增,研究提出以線性規劃為基礎的多目標路由框架,透過影子價格與雙價控制在毫秒級決策下同時優化吞吐、延遲與尾部效能,該框架將批次槽位與 KV 快取記憶體視為時間耦合資源,並以可解釋的權重將吞吐、端延遲、時間與尾部延遲分解為單請求獎勵,使路由決策透明且,實驗顯示相較傳統啟發式顯著提升表現。

深度分析
Aristotle說心靈離不開影像,研究提出MentalThink以SVG作為可執行的視覺思考機制,模型在多輪推理中生成、渲染與解讀向量圖形,提升空間理解。實驗顯示在VSIBench與MindCube上分別達55.1%與76.0%精度,顯示向量圖形成為可驗證的思考工作區。

深度分析
本篇報導聚焦 Human‑Centric Reflective Architecture(HCRA),一套將大型語言模型與人類校準模型結合的決策框架。研究將人機協同決策抽象為 AI 代理人與使用者之間的隨機遊戲,透過強化學習與迭代式語言反思,使 AI 推薦在測試時即能根據使用者偏好與限制自我調整。

深度分析
隨著預測未來事件成為通用人工智慧測試平台,研究提出首個自動化預測市場交易代理Raven-Agent,透過明確的交易層模組化選擇、部位大小與風險控制,與任意預測模型可組合。實驗在封存的Polymarket資料回放中,唯一實現正報酬與正風險調整報酬,此結果顯示交易層設計對獲利關鍵。

深度分析
隨著大型語言模型在醫學領域的應用深化,傳統計算基準僅支援單一工具且需明示目標計算器。研究團隊推出MedCalc‑Pro,收錄2268例、77種計算器,涵蓋單、多人與嵌套計算情境,並建構多工具選擇與依賴關係的代理框架。實驗顯示該框架在所有測試任務上均優於現有方法。

深度分析
SwarmResearch以ShepherdAgent统筹多個SearchAgent,在各自git分支上以局部上下文探索,破解長期編碼代理只聚焦單一路徑的限制。實驗在15項開放式優化任務中,13項表現優於或相當於最先進的LLM演化與多代理系統,且能依搜尋深度自動調整平行度,提升解決方案多樣性與品質。

深度分析
在部分可觀測的強化學習任務中,ASK框架僅提供自我觀測,未能有效利用小型語言模型。研究提出ASK+,加入部分揭露的地圖與已訪位置等情境化提示,使模型在不確定性門檻觸發時提供修正。實驗顯示ASK+在FourRooms、DoorKey與HigherLower的成功率與獎勵均顯著超過原ASK。