深度分析
YUKTI:將自然語言轉化為可驗證決策,終結 LLM 的「計算擬態」風險
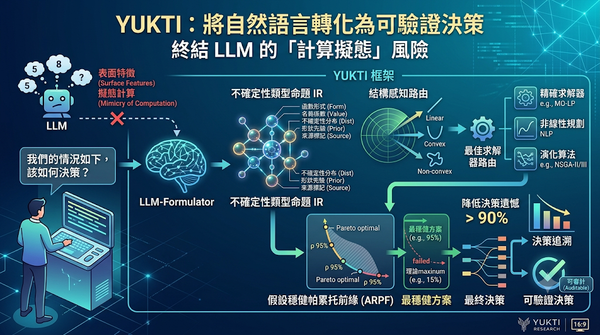
針對大型語言模型在決策時常出現缺乏實質計算基礎的計算擬態問題,研究者提出 YUKTI 框架。該系統利用不確定性類型命題 IR 將自然語言轉化為量化模型,並透過結構感知路由自動選擇求解器,結合假設穩健帕累托前緣在不確定參數下尋找最穩健方案。實測顯示 YUKTI 能將決策遺憾降低 90% 以上,將 LLM 定位為建模工具而非直接求解器。
深度分析
針對大型語言模型在決策時常出現缺乏實質計算基礎的計算擬態問題,研究者提出 YUKTI 框架。該系統利用不確定性類型命題 IR 將自然語言轉化為量化模型,並透過結構感知路由自動選擇求解器,結合假設穩健帕累托前緣在不確定參數下尋找最穩健方案。實測顯示 YUKTI 能將決策遺憾降低 90% 以上,將 LLM 定位為建模工具而非直接求解器。
深度分析
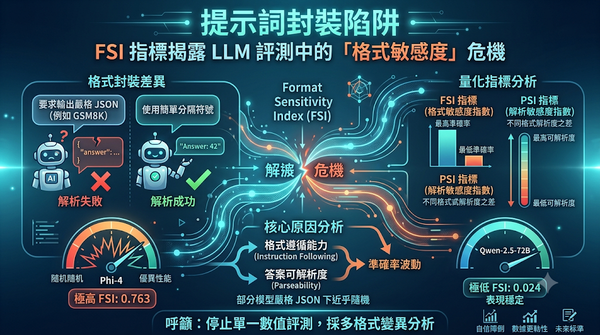
大型語言模型在基準測試中常因提示詞封裝格式的不同而導致分數劇烈波動。本研究引入格式敏感度指數 FSI 與解析敏感度指數 PSI,透過 14 萬次生成實驗分析多款模型在不同格式下的表現。結果發現部分模型在嚴格 JSON 格式下準確率近乎隨機,但在簡單分隔符號下表現優異,顯示格式遵循能力是影響評測結果的核心因素。研究呼籲業界應停止單一數值評測,改採多格式變異分析以確保結果真實。
深度分析
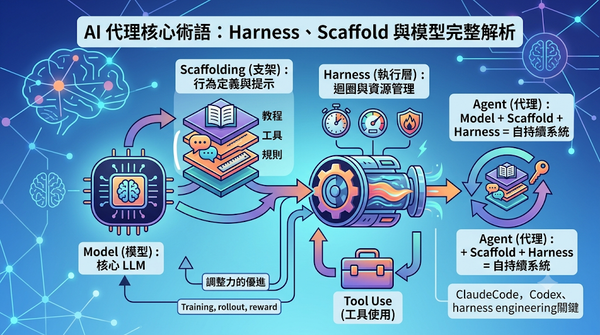
隨著AI代理快速發展,術語混亂;本文釐清model、scaffold、harness、agent等概念,說明它們在訓練與推論的分工,並指出正確用詞有助於系統設計與跨框架溝通,預期將推動更一致的開發與評估流程。比ClaudeCode、Codex框,說明harnessengineering企業AI代理自動化關鍵。
深度分析
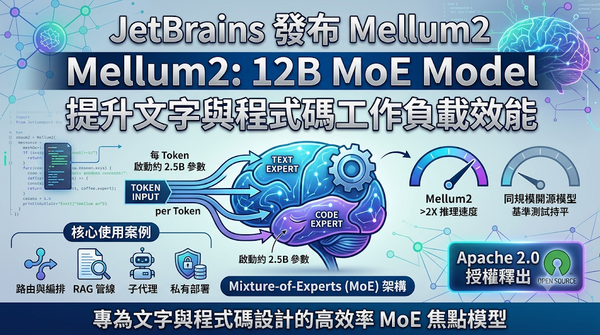
JetBrains於2026年6月發佈Mellum2,這款12 B參數的Mixture‑of‑Experts模型專為文字與程式碼設計。模型每個token僅啟動約2.5 B參數,推理速度比同規模開源模型提升逾兩倍,且以Apache2.0授權釋出,提升部署彈性與成本效益。
深度分析
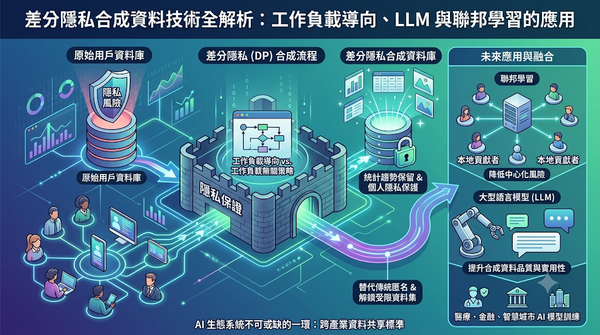
隨著可公開的人類資料日漸枯竭,研究者轉向差分隱私合成資料以保護使用者隱私。差分隱私合成資料在保留原始資料統計趨勢的同時,提供嚴格的個人資訊保護,並可取代傳統的去識別化方法。此技術有望解鎖受限資料集,促進AI模型訓練與商業應用。未來結合聯邦學習與大型語言模型,將提升其實用性。
深度分析
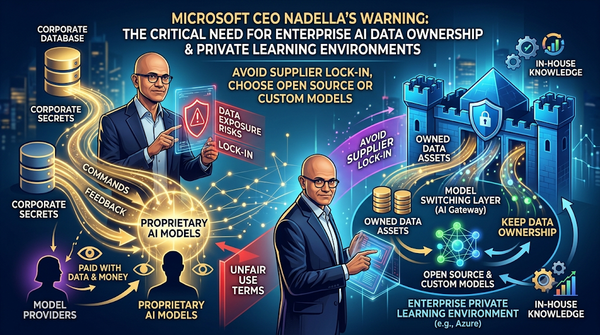
AI企業使用大型模型時,會把自家機密資訊餵給模型提供者,可能成為未來競爭者。微軟執行長納德拉警告,企業付出金錢與資料雙重代價,建議保留資料所有權並採用開源或自建模型。此趨勢或改變AI生態。模型會從企業的指令與修正中學習,形成不可買的知識。納德拉主張企業在雲端建置學習環境使用模型切換層避免鎖定供應商。

深度分析
OpenEnv於2026年獲得多家AI巨頭支援,提供可與任意模型、工具串接的代理執行環境,採用Gymnasium風格API及HTTP/WebSocket通訊,讓訓練與部署更一致,並由Meta‑PyTorch、Nvidia等組織共同治理,期望成為跨平台標準。

深度分析
HuggingFaceKernels推出新「kernel」倉庫類型,加入受信出版者與代碼簽署機制,提升自訂核心的安全與可發現性,預計加速AI開發者採用與生態成長。同時,CLI被重新分離,支援Torch Stable ABI與Apache TVM FFI,為代理式核心開發提供基礎。

深度分析
Allen AI 推出的 DiScoFormer 以 Transformer 同時估算資料分布的密度與分數,訓練使用高斯混合模型生成的樣本。實驗在100維度上顯示密度誤差比最佳KDE低逾37倍、分數誤差減少約6.5倍,且記憶體需求更佳。此技術有望降低高維度分析成本,推動生成模型與科學模擬等領域創新。

深度分析
隨著 AI 代理在科研領域崛起,Paper‑replication 工作流被設計用於自動再現科學機器學習論文。它將論文聲稱拆解成目標,記錄方法、執行實驗、比對結果,並以工作空間與驗證檢查作為完成依據。實驗顯示四篇論文的158項聲稱全部在工作空間內得到匹配,證明此流程可提升再現性與審核可靠度。
深度分析
本研究提出一套可復現的流水線,將公開 Zoom 會議影片轉換為具說話者身分標記的逐字稿,並加入人物檔案與實用行動標籤。透過多模態說話者連結(視覺框框、音訊特徵、文字上下文)自動對應真實姓名,接著以參數效能微調(PEFT)將大型語言模型(LLM)調整為「行動感知」人格模型。

深度分析
隨著網路攻擊日益增多,標記資料昂貴且稀缺。研究提出AutoGraphAD,利用異質變分圖自編碼器在無標記資料下偵測異常,並以重建誤差計算異常分數。實驗顯示其偵測效能與Anomal‑E相當,訓練與推論速度分別快1.18與1.03個量級,顯著提升部署效率。