深度分析
GAE:結合圖形神經網路與強化學習的 LLM 演化搜尋框架提升符號迴歸效能
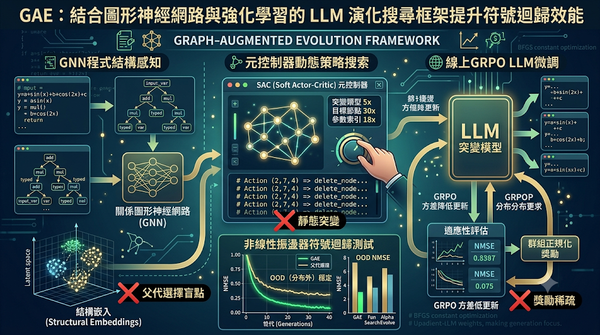
隨著大型語言模型結合演化搜尋成為科學發現新趨勢,GAE框架透過圖形神經網路、強化學習元控制器與線上GRPO微調,解決父代選擇盲點、獎勵稀疏與靜態突變三大瓶頸,於非線性振盪器符號迴歸測試中取得最佳NMSE,顯示結構感知演化顯著提升搜尋效率與效能。
深度分析
隨著大型語言模型結合演化搜尋成為科學發現新趨勢,GAE框架透過圖形神經網路、強化學習元控制器與線上GRPO微調,解決父代選擇盲點、獎勵稀疏與靜態突變三大瓶頸,於非線性振盪器符號迴歸測試中取得最佳NMSE,顯示結構感知演化顯著提升搜尋效率與效能。
深度分析
研究聚焦於資料不平衡對抗虛假相關的影響,發現高比例捷徑樣本在容量足夠的模型中會使反捷徑梯度放大,促使注意力電路重組,提升對抗測試準確率。此發現挑戰了傳統上必須平衡資料的做法,並提供了一條利用不平衡提升模型魯棒性的路徑。實驗在多種二元與三元任務上皆驗證,顯示此機制與資料比例偏離隨機基準的程度相關。

深度分析
在大規模網路語料庫中,FindMyText 以指紋鏈結機制偵測文字包含,提升版權核查準確度;它結合 Winnowing 減少指紋數量,並支援分散式磁碟索引;實驗證明在 Wikipedia、ArXiv 與一般網頁資料上,該方法的 AUC‑ROC 與高召回率皆優於傳統指紋計數方式。
深度分析
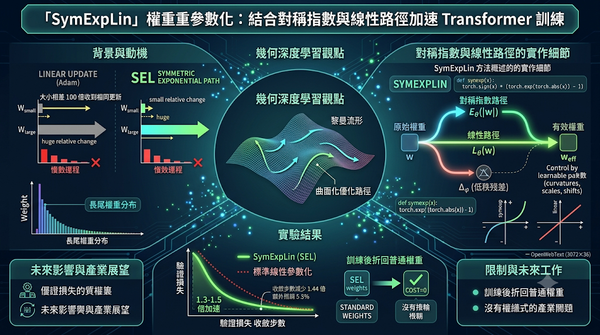
研究發現,Transformer訓練的權重分布呈重尾,線性參數化使大、小參數的相對更新差異極大。作者提出SymExpLin(SEL),結合對稱指數與線性雙路徑,使更新在對數空間呈比例放大。實驗顯示SEL在多種模型規模上將驗證損失收斂步數縮短約1.3‑1.5倍,且訓練結束後可折回標準權重,成本不變。

深度分析
研究顯示惡意網站可誘導 AI 瀏覽器進入虛構世界,繞過安全防護,讓攻擊者執行代碼抽取或竊取密碼等破壞行為。此手法名為 BioShocking,已在多款 AI 瀏覽器(如 ChatGPT Atlas、Claude 插件)成功示範,凸顯現有防護的根本缺陷。研究者指出,攻擊者利用謎題讓模型接受錯誤答案,進而進入幻想狀態,使原本的 guardrail 失效,並可能導致私密倉庫或內建密碼管理器資料外洩。
深度分析
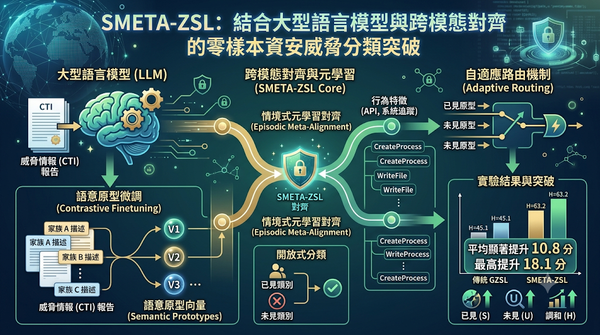
隨著新興惡意程式層出不窮,傳統防禦難以及時取得標記資料。研究提出 SMETA‑ZSL,透過對比微調的語言模型產生語意原型,並以情境式元學習對齊行為特徵,實現開放式零樣本威脅分類。實驗顯示在七項基準上平均顯著提升 10.8 分,最高可達 18.1 分。
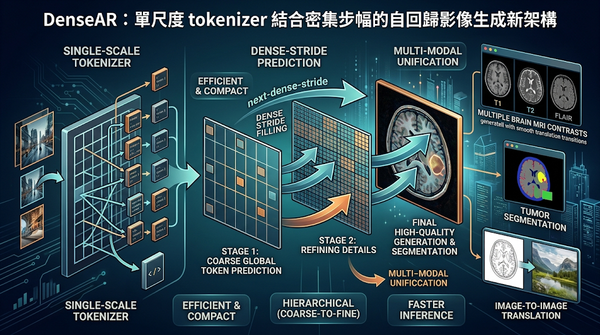
深度分析
本研究提出DenseAR,以單尺度tokenizer結合密集步幅預測,實現粗到細的階層生成,同時保持單格緊湊。實驗在ImageNet與多對比腦部MRI上顯示,品質與效率均優於傳統光柵或多尺度模型,且首次在單一自回歸模型中同時支援跨模態翻譯、條件生成與腫瘤分割,預示AI影像平台未來可朝通用化發展。

深度分析
隨著音訊 Deepfake 技術演進,偵測模型雖有高準確率,卻常隱藏性別性能差異。本研究透過 ASVspoof5 數據集,對比 LogSpectrogram 與 WavLM-Base+ 在不同訓練性別組成下的表現,發現代表性不足的性別錯誤率較高。研究進一步證明後處理校準無法消除等錯率差距,強調公平性必須在訓練階段解決。

深度分析
隨著視訊監控與可穿戴裝置普及,持續觀察與長期記憶成為關鍵需求。ReflectWorld-MM以實體為中心,結合多尺度情節記憶、演化語意記憶與程序記憶,建立層級化外部資料庫。六項長影片基準測試皆領先,顯示其在實體追蹤與跨時段推理上的優勢,此系統亦支援即時串流與多模態查詢。

深度分析
研究聚焦於編碼代理在修正程式碼時實際需求的上下文,測試完整檔案、結構化摘要與壓縮表示。結果顯示,唯一關鍵是被編輯的程式碼本身,摘要與類別骨架幾乎不提供資訊;壓縮上下文僅需約19,000token,即可達到與完整檔案相同的解決率。此發現對未來 AI 編碼工具的設計具有重要啟示。
深度分析
在大型Transformer推論中,KV快取記憶體是瓶頸。研究比較資料無關的TurboQuant與資料自適應的SpectralQuant,測試多種量化技術。結果顯示,重尾資料下TurboQuant表現更佳,結構化資料在足夠位元預算時SpectralQuant優於前者。

深度分析
MoE大語言模型在3.5D多晶片系統中會出現熱專家負載偏斜,導致計算、記憶體與連結壓力不均。研究提出HCRMap框架,根據熱度、遷移成本與資源壓力動態調整熱專家副本的層級配置。實驗顯示在預填與解碼階段的端到端延遲分別降低約43%與46%顯著。