
深度分析
多領域測試時縮放:生成式結果驗證模型(gORM)超越過程驗證模型的實證分析
研究重新評估多領域測試時縮放的獎勵模型,發現生成式結果驗證模型在14個領域均表現最佳,挑戰以步驟為單位的精細監督假設,並指出長推理鏈與標籤噪聲是關鍵影響因素,此結果促使未來在法律、醫療等高風險領域的 LLM 部署,更傾向採用生成式結果驗證以提升可信度。
深度分析
研究重新評估多領域測試時縮放的獎勵模型,發現生成式結果驗證模型在14個領域均表現最佳,挑戰以步驟為單位的精細監督假設,並指出長推理鏈與標籤噪聲是關鍵影響因素,此結果促使未來在法律、醫療等高風險領域的 LLM 部署,更傾向採用生成式結果驗證以提升可信度。

深度分析
隨著大型語言模型可自行使用工具,研究推出DeepTravel框架,利用沙箱與階層獎勵模型訓練自動旅遊規劃代理人,框架採階層獎勵先驗證時空可行性,再以回合檢查細節,並透過失敗回放提升推理,實驗顯示小型模型超越前沿模型,提升行程品質,已於滴滴企業版上線,顯示此技術可加速小模型商業化。
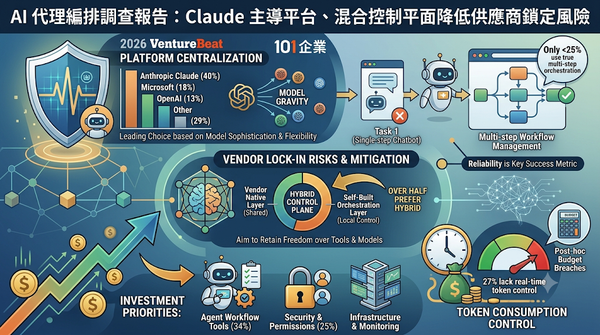
深度分析
VentureBeat2026年調查顯示,企業正把AI代理編排集中於模型提供商平台,尤其以Anthropic的Claude為主。調查指出,多數所謂「代理」仍是單一提示的聊天機器人,真正的多步驟編排僅佔四分之一以下,且超過半數企業擔憂供應商鎖定。

深度分析
隨著大型語言模型代理人從桌面延伸至手機,PalmClaw 以原生手機框架直接管理記憶、工具與執行迴圈,將裝置功能以具結構參數的工具呈現。實驗顯示任務成功率提升約 11.5%,完成時間縮短逾 94%。此設計降低對雲端依賴,提升資安與使用者隱私。同時採用 AGPL 授權,鼓勵社群共同擴充多模態感測與自動化功能。
深度分析
研究針對量化語言模型的安全性,提出J‑space內部表示測量方法,透過JacobianLens在回應決策點讀取危險訊號,並以SafetyAUC、ComplianceAUC等指標比較FP、INT8、INT4量化層級。結果顯示部分模型安全辨識仍堅固,合規性提升可能增加危險指令違規回應,對未來模型部署與量化策略具重要啟示。
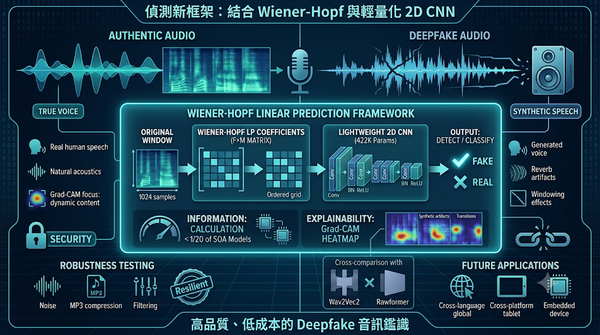
深度分析
隨著合成語音技術快速進步,音訊Deepfake偵測成為多媒體鑑識關鍵。研究提出以Wiener‑Hopf線性預測結合輕量化2DCNN的可解釋設計,直接連結分類結果與聲學特性。實驗顯示在多項基準資料上達到與最先進模型相當的偵測率,同時計算量僅為其十分之二。

深度分析
研究針對在JetsonOrin等低功耗晶片上部署Vision‑Language‑Action模型的延遲問題,提出以未來校正為核心的Jetson‑PI方法,透過輕量化未來環境預測與信心排程,同步提升推論頻率與反應速度。實驗顯示在LIBERO基準上控制頻率提升逾八倍,成功率提升近十五%。
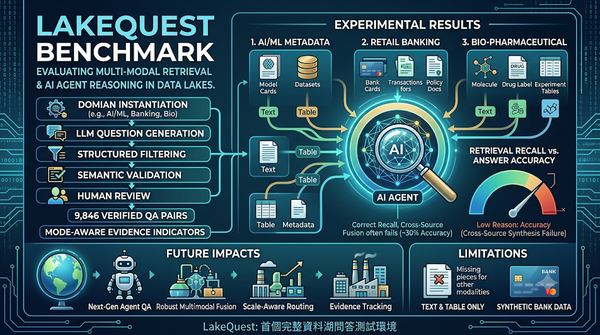
深度分析
研究指出現實資料湖缺乏有效評測環境,提出LakeQuest基準以表格、文字與元資料混合測試檢索與推理。測試顯示即使檢索正確,跨來源合成仍常失敗,凸顯未來需要更健全的多模態組合與證據追蹤機制。基準涵蓋AI/ML元資料、零售銀行與生醫藥物三大領域,測試11種模型發現檢索高但推理正確率僅約30%。

深度分析
單張影像深度估計近年多採用擴散模型,但在保持銳利邊界與細部結構上仍有挑戰。ARDepth以階層式自回歸方式,結合多尺度視覺條件與語意感知指導,逐層構建深度圖。實驗顯示其在多項零樣本基準上達到或超越最先進表現,顯示自回歸生成是幾何建模的可行新方向。預期此架構將推動深度模型商業化與開發者生態的多元創新。

深度分析
FinMMEval 2026 Task 3 評估 LLM 交易代理,Fin‑Analyst 以八位專家結合新聞、SEC、基本面等資訊,透過 Meta‑Agent 為特斯拉 (TSLA) 產生 +13.51% 報酬率、Sharpe 4.10,且在比特幣 (BTC) 採用三信號投票維持資本。

深度分析
隨著大語言模型進入協作工作,研究者需要可重現的 AI 夥伴實驗平台。TRAIL 以 Big Five 人格模型結合雙記憶與選擇性發言管線,讓 AI 角色可在即時聊天室中以固定比例參與,並自動匯出多層次分析資料。實驗顯示,僅改變 AI 人格即能在貢獻評分與團隊氛圍上產生相反效果,證明平台可精準操控團隊動態。
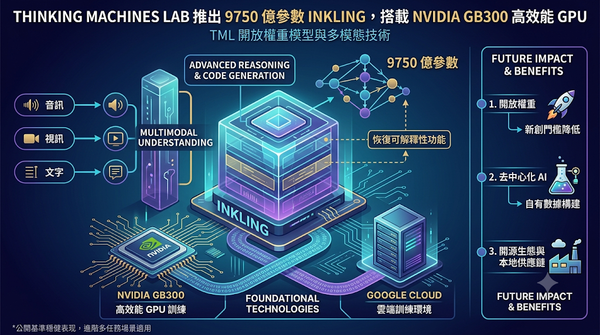
深度分析
ThinkingMachinesLab於2025年成立,發布開放權重模型Inkling,使用NvidiaGB300晶片在Google雲端訓練,擁有9750億參數,能同時理解音視訊與文字並支援程式碼生成,預計將推動AI開源生態與本地供應鏈需求。