
深度分析
Mycelium 主動共享上下文圖:提升 AI 代理人協作與科學發現效率
研究指出,Mycelium透過主動共享上下文圖即時連結人類與AI代理人的科學資訊,提升跨領域協作效率。相較於AWS OpenSearch Serverless的即時查詢層Mycelium更能保留上下文證據溯源。實驗顯示,較單一大型模型可加速發現、降低token消耗,預期重塑企業AI代理人部署與供應商格局。
深度分析
研究指出,Mycelium透過主動共享上下文圖即時連結人類與AI代理人的科學資訊,提升跨領域協作效率。相較於AWS OpenSearch Serverless的即時查詢層Mycelium更能保留上下文證據溯源。實驗顯示,較單一大型模型可加速發現、降低token消耗,預期重塑企業AI代理人部署與供應商格局。

深度分析
研究以 Belnap 四值型意向一階邏輯為基礎,加入機率計算與最大熵神經網路,提升機器人自我推理與不確定句子處理能力,展示了在強 AI 方向的可行性。作者亦提出全域與局部對稱轉換保護知識庫,並以 Shannon 最大熵推導機率密度,由神經網路即時產生,為未來 AI 安全與可解釋性提供新視角。

深度分析
隨著 AI 代理需要跨會話保存任務狀態,Oracle 推出以 Oracle Database 為基礎的 Agent Memory,提供從訊息擷取、摘要、篩選到語意檢索的完整生命週期管理。實驗顯示在 LongMemEval 基準上達 93.8% 正確率,且使用的 token 數僅為傳統平面歷史的十分之一,顯著提升效能與治理。
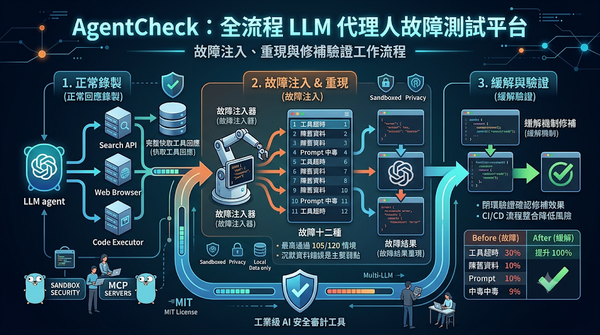
深度分析
隨著LLM代理人廣泛部署,工具失效成為關鍵風險。AgentCheck以MCP伺服器為介面,先錄製正常回應,再注入十二種工具故障,提供可重現‑介入‑驗證的工作流程。實驗顯示最高代理人在120場景中通過105場,揭露沉默的資料品質錯誤是主要弱點,亦值得關注。

深度分析
Shippy是AI2為海事領域打造的高可靠性代理人,透過系統提示、技能檔與可配置的CLI抽象化SkylightAPI,確保答案可追溯與資料隔離。評估框架證實其在查詢與守護規則上表現穩定,將推動未來海域監控與環境平台的擴展。同時支援模型路由與跨執行緒記憶功能。
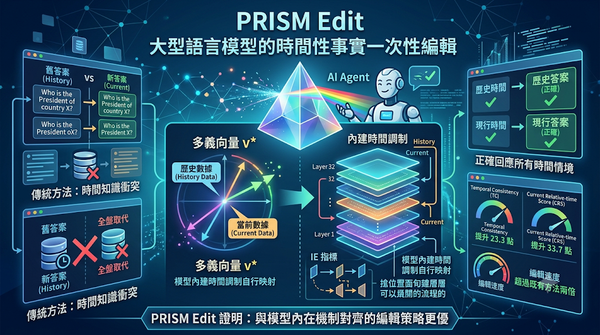
深度分析
隨著知識持續變動,傳統知識編輯會在時間上產生衝突。研究提出PRISM Edit以單一多義向量結合模型內建時間調制,無需改架構即可同時正確回應現行與歷史時間。實驗顯示在TimeConflict與CounterFact上TC提升23.3點、CRS提升33.7點,且速度超過兩倍。

深度分析
隨著Transformer成為AI應用核心,其錯誤會影響系統可靠性。研究提出RepTran,結合變異性神經元分數與雙向分數,透過差分演化搜尋修正FFN權重。實驗顯示平均修復率達74.7%,顯著優於現有方法。在CIFAR-100與Tiny-ImageNet測試中,最高95.2%修復率,耗時約476秒。

深度分析
本研究提出 Resource2Skill 框架,透過自動化流程將教學影片、程式碼庫、文章與參考素材等多模態人類資源萃取為可執行的技能,並以階層式 Skill Wiki 組織。技能條目結合結構化文字、可執行程式碼與視覺範例,讓大型語言模型在執行軟體創作任務時能即時檢索、組合與補足缺口。

深度分析
近年向量嵌入外洩風險升高,研究提出Shard方案將中心化嵌入分為公開前綴與私密殘差,後者以多格密鑰逐格旋轉,並在CKKS下全維度重新排序。實驗顯示在五種編碼器上,Shard能在保持原始檢索品質的同時,使已知明文對齊攻擊所需錨點數提升至約256倍,且公開前綴泄漏的鄰近結構大幅降低。

深度分析
本研究針對模組算術的結構缺陷提出新嵌入方法。PrimeFourierEmbeddings以質數索引的cos、sin配對直接呈現餘數,並透過中國剩餘定理選取相關質數通道。實驗證實相關通道與無關通道的專精度差異超過500倍,全部測試模組均達到完美準確率。

深度分析
隨著大型語言模型在軟體開發上的突破,硬體設計仍面臨錯誤風險。本研究提出結合形式化方法的逐步細化框架,讓LLM在每一步都受到可驗證規則約束,最終產生正確的RTL程式。實驗顯示此流程在VerilogEval基準上穩定生成符合規範的硬體描述。此技術有望加速晶片設計流程,降低人力成本。
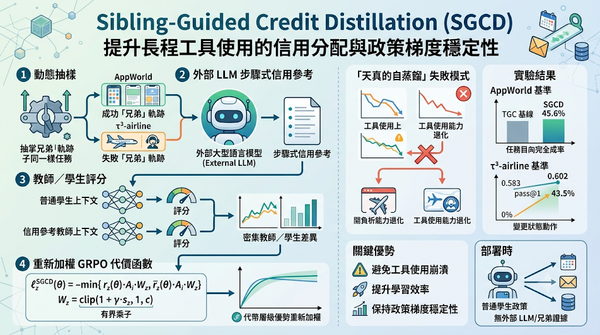
深度分析
研究聚焦長程工具使用強化學習,提出以兄弟樣本引導的信用蒸餾(SGCD)作為信用分配機制,透過動態抽樣與外部語言模型產生步驟式信用參考,重新加權GRPO代價函數。實驗在AppWorld與τ³‑airline基準上分別提升至45.6%與0.602的pass@1,證明SGCD能避免自蒸餾破壞工具使用。