深度分析
Traccia:以 OpenTelemetry 為基礎的 AI 系統治理平台全解析
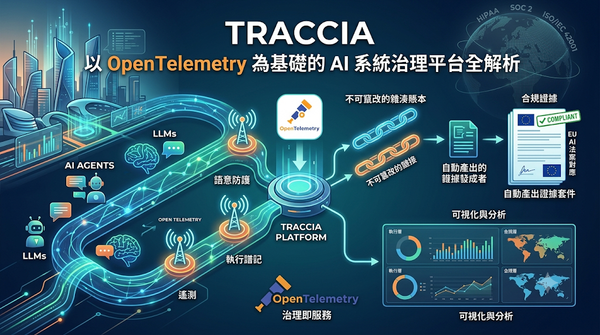
隨著大型語言模型與自主AI代理快速崛起,現有治理工具難以滿足EU AI法案的透明與問責要求。Traccia以OpenTelemetry為基礎,將遙測、語意防護與執行譜記整合至不可竄改的雜湊賬本,自動產出符合多條款的合規證據,縮短治理與合規的最後一哩路。
深度分析
隨著大型語言模型與自主AI代理快速崛起,現有治理工具難以滿足EU AI法案的透明與問責要求。Traccia以OpenTelemetry為基礎,將遙測、語意防護與執行譜記整合至不可竄改的雜湊賬本,自動產出符合多條款的合規證據,縮短治理與合規的最後一哩路。

深度分析
本篇報導深入探討生成模型的控制機制,指出傳統的提示、指導尺度與屬性標籤(統稱旋鈕)只能在資料預先設定的「預算」內調整屬性,而大量未被旋鈕覆蓋的範圍只能透過示例(具體實例)來引導。研究提供了以訓練資料簡易審核預算的方法,並示範在影像與晶體結構兩個完全不同領域中,示例導向如何突破旋鈕的限制,實現更完整的屬性移動與更高的表現力。
深度分析
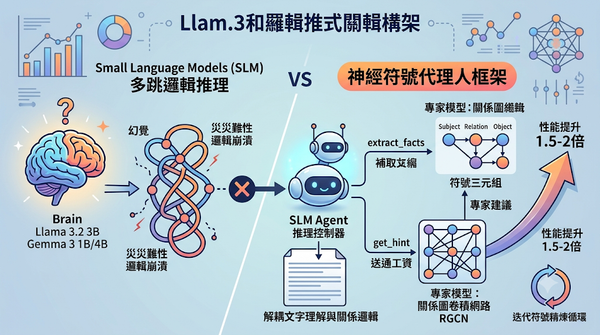
面對大型語言模型部署成本高昂,研究者提出神經符號代理人框架,利用小型語言模型結合關係圖卷積網路(RGCN)來強化其邏輯推理。該方法將 SLM 轉化為代理人,透過提取符號三元組並獲取專家建議來進行多跳推理。實驗結果顯示,此舉能將推理性能提升 1.5 至 2 倍,但同時揭示了資訊提取瓶頸與錯誤累計效應,為低資源環境下的 AI 推理提供了新方向。

深度分析
受人類以語言傳遞空間資訊的啟發,研究團隊提出 Dialogue Place Recognition(DlgPR)概念,將定位問題重新定義為一場互動式對話推理。系統結合跨模態漸進學習檢索器(CMPL)與大型多模態語言模型 DQ‑pilot,透過主動提問逐步釐清模糊描述,並以難度指標與位置檢索增益作為課程學習指導。

深度分析
目前多鏡頭影片生成常面臨實體特徵漂移問題,導致角色或場景在不同鏡頭間不一致。研究團隊提出 GroundShot 框架,透過建立實體級視覺記憶體並將生成順序與敘事順序解耦,優先生成高品質參考鏡頭以建立標準參考,再將其用於指引引導生成。實驗證明該方法能顯著提升多鏡頭影片的一致性,且無需對模型進行額外訓練或修改。

深度分析
隨著 MoE 模型崛起,訓練成本飆升。NVIDIA NeMo AutoModel 以 Expert Parallelism、DeepEP 與 TransformerEngine 核心,讓微調速度提升 3.4–3.7 倍,GPU 記憶體降低 29–32%。此技術將助力大模型在多節點環境下可行,推動 AI 基礎設施演進。

深度分析
2026年推出的EveryEvalEver(EEE)與HuggingFace社群評估現在可互通,透過單一JSON結構統一報告模型評分,並自動轉換為YAML,提升結果可追蹤性與再現性。此舉填補了評分分散、格式不一的缺口,讓研究者與政策制定者能更快速比對模型安全與效能。
深度分析
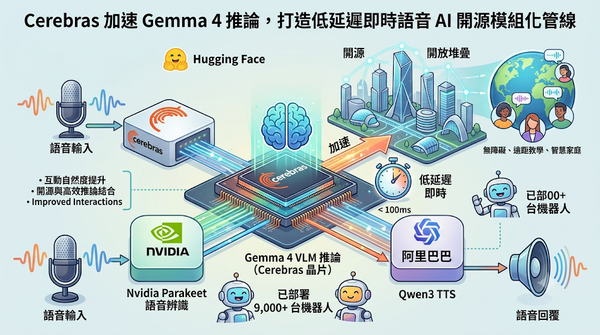
Hugging Face 與 Cerebras 合作,推出以 Gemma 4 為核心的即時語音 AI,採用模組化開放堆疊結合 Nvidia Parakeet、Cerebras 晶片與阿里巴巴 Qwen3 TTS,將回應延遲縮至即時,已於 9,000 多台機器人部署,提升互動自然度並示範開源與高效推論的結合。

深度分析
隨著模型與資料常分布於不同雲端,SkyPilot結合HuggingFaceStorage提供hf://掛載,實現跨雲零出口讀取,降低跨區傳輸費用,同時支援即時懶載與Xet去重,提升訓練與推論效率,兼容AWS、GCP、Azure等二十餘雲平台。
深度分析
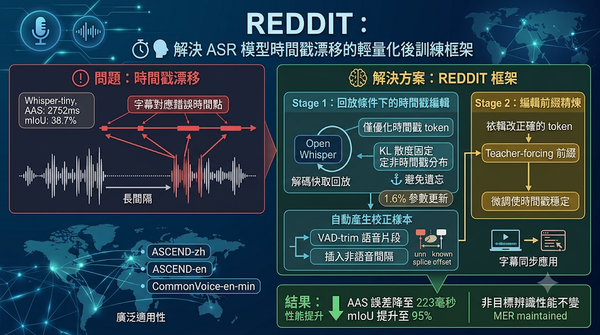
自動語音辨識系統在長時間靜音間隔後會出現時間戳漂移,導致文字內容雖正確卻對應錯誤時間點。研究提出REDDIT兩階段後訓練框架,利用模型自我回放編輯時間戳,同時凍結非時間戳分布以防遺忘。實驗顯示在Whisper‑tiny上,長間隔mIoU提升至95%,AAS誤差降至223毫秒,且非目標辨識性能保持不變。

深度分析
HuggingFace近期將Transformers整合為vLLM模型後端,讓LLM使用原生加速。新後端利用torch.fx靜態分析與AST重寫,將注意力等關鍵層融合至vLLM核心kernel,實現與手寫原生實作相當的吞吐。測試在4B、32B與235BMoE模型上均達到或超過原生效能,降低部署門檻。

深度分析
隨著語音成為AI主要介面,Hume推出的RealWorldVoiceEQ以百萬級人類評分測試超過40種語音模型,聚焦語調、情緒與說話者身份等人類感知指標,發現現有基準普遍高估實際表現,凸顯需以新測量層提升商業應用可靠度。此結果促使業界重新思考模型訓練與部署策略,並加速人類回饋迴路的整合。