深度分析
AI 代理評估轉向對比分析:LangChain、Conviva、CoreWeave 高層揭露新思維
AI 代理評估出現新典範:單一對話評分可能掩蓋產品缺陷。LangChain、Conviva 與 CoreWeave 專家提出對比分析,比較用戶群體與基線以找出問題。評估標準成為動態產品規格,並建議從頂尖模型逐步縮小至小型模型或正則表達式,大幅降低成本。人類監督仍不可或缺。
深度分析
AI 代理評估出現新典範:單一對話評分可能掩蓋產品缺陷。LangChain、Conviva 與 CoreWeave 專家提出對比分析,比較用戶群體與基線以找出問題。評估標準成為動態產品規格,並建議從頂尖模型逐步縮小至小型模型或正則表達式,大幅降低成本。人類監督仍不可或缺。

深度分析
中國AI公司Moonshot與阿里巴巴接連發布新模型Kimi K3和Qwen3.8,號稱性能可與OpenAI和Anthropic頂尖模型匹敵,且採取開源策略。兩者參數規模分別達2.8兆與2.4兆,強調低成本高效能,進一步加劇美中AI競爭,挑戰美國晶片出口管制效果。

深度分析
手寫文字辨識因語言筆畫差異而困難重重。本研究讓 GPT-5、GPT-4o 與 Claude Sonnet 4 扮演神經架構設計師,透過閉環回饋自動生成並優化模型。在阿拉伯語、英語、波斯語上,平均準確率超過 93%,最佳達 98.1%,推論時間約 41 毫秒,驗證了 LLM 驅動自動機器學習的可行性。
深度分析
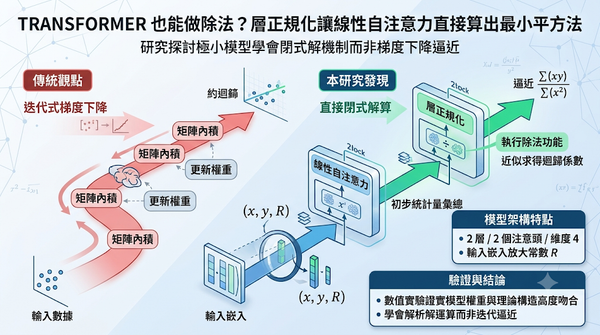
研究探討 Transformer 在上下文學習中,如何利用線性自注意力結合層正規化,直接近似求得線性迴歸的最小平方法,而非傳統的梯度下降迭代。作者構建了一個僅有 2 層、2 個注意頭、維度 4 的小型模型,並在加入 ℓ1 正則化的訓練下,證實模型會學會以層正規化執行除法運算,產生閉式解。

深度分析
隨著文字生成影像技術快速發展,評估生成內容的文化真實性成為公平可信的關鍵。研究提出基於4.2億參數多模態大語言模型的隱性文化對齊獎勵模型,結合文化探測與跨注意力機制,直接預測標量分數。實驗在3,323組測試影像上達到80.54%配對正確率,並以0.21秒的延遲比傳統VQA評估快十倍。

深度分析
研究以視覺皮層的水平連結為靈感,提出帶非因子先驗的稀疏編碼模型,利用去噪分數匹配訓練可視為最小化擴散模型。實驗顯示該模型在去噪與輪廓補全上媲美黑盒擴散,同時揭示了連續結構變形的機制。學習得到的交互矩陣與V1表層水平連結相似,並發現大量潛在變量自動脫離視覺輸入,形成全局一致的階層表示。

深度分析
在長回合代理任務中,傳統均勻抽樣浪費資源;PaTR透過任務導向的過程評分器,動態擴展有前景的分支並及早剪枝,於FrozenLake與SWE‑Bench提升9.3與5.0分,證明樹式展開提升探索效率。保留剪枝失敗樣本作負向訓練,提升GRPO相對優勢估計。

深度分析
本研究針對含有不可直接操控變數的因果強盜問題,提出結合貝氏框架的因果湯普森抽樣與資訊導向抽樣(IDS)演算法。透過將觀測分佈的條件機率表作為未知參數,利用共享的因果機制跨介入更新獎勵預估,並在 IDS 中明確量化蒙特卡羅近似所帶來的額外誤差。
深度分析
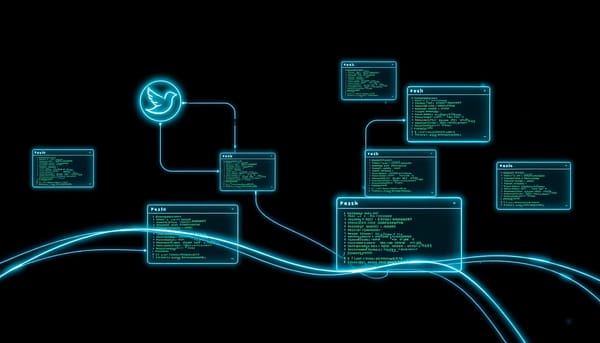
Botmux以直接橋接AI編程CLI為設計核心,省去SDK包裝,支援多種CLI如ClaudeCode、Codex、Cursor等。透過飛書Daemon自動為每個會話啟動獨立CLI進程,並以流式卡片與可交互Web終端即時回傳結果。此架構提升開發者協作效率,並降低升級維護成本。
深度分析
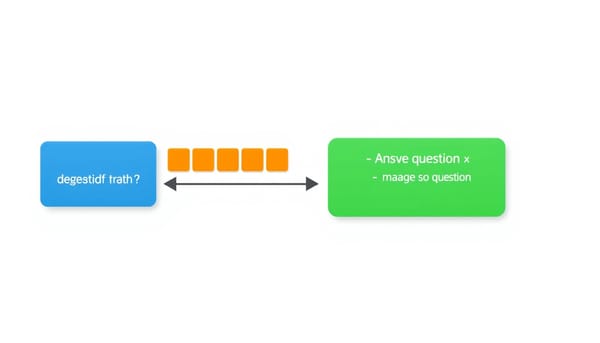
在視覺語言模型(VLM)中,直覺上認為先給問題能引導模型注意影像內容,然而實驗發現「問題先行」的提示方式在多項基準測試上表現最差,形成所謂的問題先行悖論。研究者透過 logit‑lens 與注意力探測證實,先問問題確實能驅動影像特徵向問題相關概念靠攏,但因問題被長長的影像序列隔離,答案產生階段幾乎不會讀取到問題,導致錯誤答案。

深度分析
物理資訊神經網路 PINN 在設計時對架構與優化參數極其敏感,傳統手動調參困難。本研究提出一套閉環演化演算法,將 LLM 作為設計算子,透過種群評估、父代突變與交叉及經驗回饋機制,自動生成可執行的 PINN 配置。實驗結果顯示,在處理一維波方程時,最高可將均方誤差降低 95.38%,證明 LLM 引導的演化搜尋具備自動化構造物理數值學習算法的潛力。

深度分析
研究人員利用新開發的 Jacobian Lens 技術,探索大型語言模型內部的資訊處理機制。該技術可識別模型準備轉化為文字的特徵空間 J-space,發現其功能與神經科學中的全局工作空間理論高度相似,能承載刻意推理與靈活的內部對話。實驗證明透過干預 J-space 可直接改變模型輸出,並揭露其隱藏的策略思考,為 AI 可解釋性與對齊研究提供新突破。