深度分析
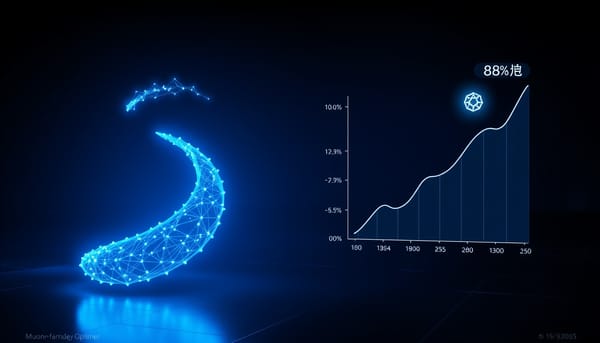
Muon 優化器在稀疏回饋代理強化學習中提升成功率達 88%
研究探討Muon優化器在稀疏回饋的長程代理強化學習中的表現,與AdamW於ALFWorld任務比較。結果顯示,在GiGPO設定下,僅對隱藏矩陣使用Muon可將驗證成功率提升約88%,且在較高學習率仍保持效能。Muon在GRPO與GraphGPO上亦有提升,於GraphGPO接近飽和時差距縮小。
深度分析
研究探討Muon優化器在稀疏回饋的長程代理強化學習中的表現,與AdamW於ALFWorld任務比較。結果顯示,在GiGPO設定下,僅對隱藏矩陣使用Muon可將驗證成功率提升約88%,且在較高學習率仍保持效能。Muon在GRPO與GraphGPO上亦有提升,於GraphGPO接近飽和時差距縮小。

深度分析
研究指出人類視覺需主動觀測,推出 ActiveVision 基準測試大型多模態語言模型的迭代視覺推理能力。實驗發現即使最先進模型也只能正確解答約十分之一,且在多項任務上得分為零;相較之下三位人類受測者平均正確率達九十六點一百分比,顯示目前模型在主動觀測上仍有明顯不足。

深度分析
AI治理正面臨一個關鍵難題:如何在系統更新、環境變動後,持續判斷AI是否仍值得信任?現有方法要不是過於抽象,無法落地到日常監控,就是只專注單一指標,無法與整體治理銜接。本研究提出一套輕量級方法論,包含形式化框架與治理程序兩大部分。

深度分析
隨著社群平台文字與圖片常出現語意衝突,研究提出HCIG層次式跨模態不協調圖網路,分別在詞彙、片語與全局層面建模不一致,並以層次注意力融合。實驗在MMSD與MultiBully上分別達85.74%準確與69.62%準確,顯示階層式圖式推理優於傳統融合。
深度分析
視覺-語言-動作(VLA)模型在機器人操作與控制任務中展現潛力,但後訓練階段因模擬器、機器人型態與任務目標的多樣性而充滿挑戰。現有雲端服務多採單租戶獨佔 GPU 模式,導致短暫或突發性工作負載成本高昂且資源利用率低落。

深度分析
一項研究在 AppWorld 基準上比較模型合併與聯合多任務強化學習,發現合併後的專家模型在任務目標完成率上與聯合訓練模型無統計差異。任務向量幾何分析顯示專家向量近乎正交,導致支援集或符號合併方法退化為均勻平均。結果表明在該設定下合併足以匹敵聯合訓練,但需注意指標敏感性。
深度分析
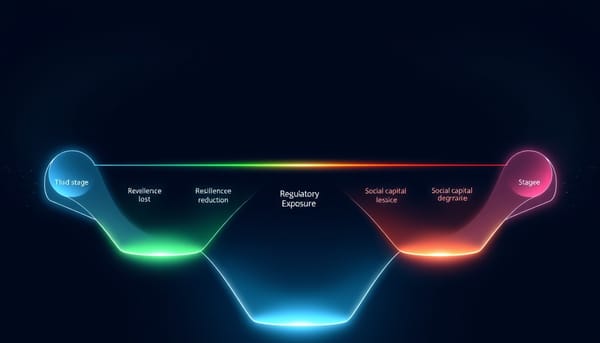
隨著企業加速導入 AI,自動化盲點頻現。研究提出 PHP‑AIO 協議,透過五關評分量化四大系統性風險:隱性知識流失、韌性降低、監管曝露與社會資本退化,並依評分給予自動化、增強、混合或保留四種決策,引導金融服務等高風險產業在部署前審慎選擇,避免長期效能與信任受損。
深度分析
本研究探討無資料知識蒸餾方法 CAKE(對比溯因知識萃取)能否應用於自編碼器這類瓶頸生成架構。作者將 MNIST 連續重建任務重新表述為每個像素的分類問題,使解碼器輸出分類 logits,從而讓 CAKE 可直接套用。
深度分析
現有駕駛世界模型多採單一抽象層級,難以兼顧長時域推理與高保真生成。Orbis 2 提出雙層預測架構:高層以壓縮 DINOv2 特徵預測長期場景,低層以 VAE 生成細緻畫面,並以擴散強制預訓練加教師強制微調。在 nuPlan、Waymo 等基準上,FVD、語意分割探測及轉向反應性均達業界最佳。
深度分析
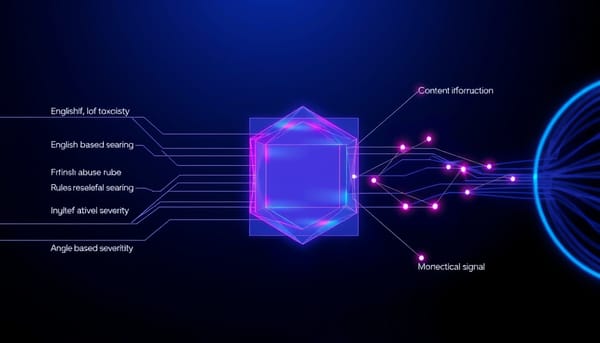
線上平台充斥混合語言與轉寫文字,現有外部毒性工具(如 Detoxify、Perspective API)在這些情境下常不可靠。本研究提出 ToxGate,一種源感知門控融合機制,能根據文字上下文動態調整對英語毒性、印度語濫用與規則式嚴重度等輔助訊號的信任程度。

深度分析
Hugging Face 近期遭自律AI代理人入侵,攻擊者利用惡意資料集觸發兩條程式碼執行路徑。公司發現商業API安全防護將偵測請求視為攻擊,導致取證受阻,最終改用自家GLM5.2完成分析。此事件凸顯AI安全防護與資安作業的衝突。此外,報告指出企業需重新檢視AI供應鏈與事故回應流程。
深度分析
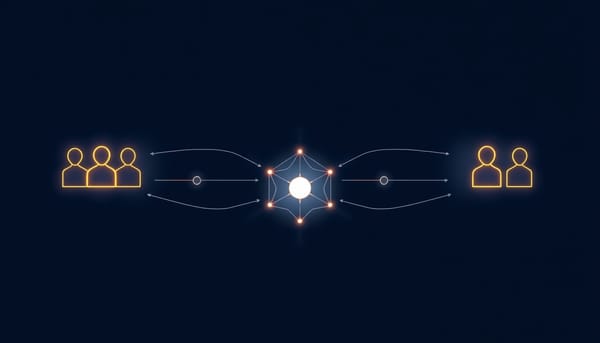
AI 代理評估出現新典範:單一對話評分可能掩蓋產品缺陷。LangChain、Conviva 與 CoreWeave 專家提出對比分析,比較用戶群體與基線以找出問題。評估標準成為動態產品規格,並建議從頂尖模型逐步縮小至小型模型或正則表達式,大幅降低成本。人類監督仍不可或缺。