
深度分析
DialogueVPR:結合跨模態檢索與大型多模態語言模型的對話式視覺位置辨識
受人類以語言傳遞空間資訊的啟發,研究團隊提出 Dialogue Place Recognition(DlgPR)概念,將定位問題重新定義為一場互動式對話推理。系統結合跨模態漸進學習檢索器(CMPL)與大型多模態語言模型 DQ‑pilot,透過主動提問逐步釐清模糊描述,並以難度指標與位置檢索增益作為課程學習指導。
深度分析
受人類以語言傳遞空間資訊的啟發,研究團隊提出 Dialogue Place Recognition(DlgPR)概念,將定位問題重新定義為一場互動式對話推理。系統結合跨模態漸進學習檢索器(CMPL)與大型多模態語言模型 DQ‑pilot,透過主動提問逐步釐清模糊描述,並以難度指標與位置檢索增益作為課程學習指導。
深度分析
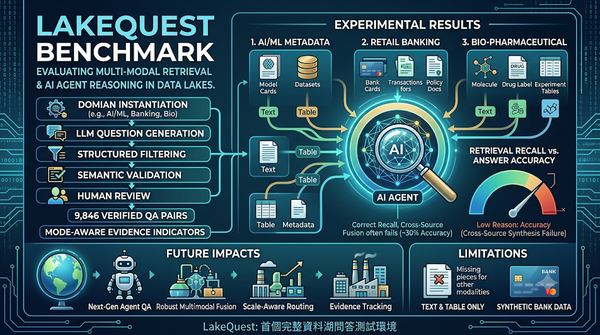
研究指出現實資料湖缺乏有效評測環境,提出LakeQuest基準以表格、文字與元資料混合測試檢索與推理。測試顯示即使檢索正確,跨來源合成仍常失敗,凸顯未來需要更健全的多模態組合與證據追蹤機制。基準涵蓋AI/ML元資料、零售銀行與生醫藥物三大領域,測試11種模型發現檢索高但推理正確率僅約30%。

深度分析
SentenceTransformers在v5.4版加入多模態嵌入與重排序功能,允許同一API處理文字、影像、音訊與影片,並支援跨模態檢索與RAG流程。模型可直接比較文字與影像向量,並提供混合式文件排序,提升視覺文件檢索精度。同時降低本地與邊緣部署門檻。

深度分析
SentenceTransformers在v5.4加入多模態支援,讓文字、影像、音訊與影片可用同一API編碼與比較,開啟視覺文件檢索與跨模態搜尋新應用,並提供多模型選擇與GPU需求說明。同時支援多模態重排序模型,可提升跨模態檢索精度,預期將加速企業多媒體資訊管理與生成式AI流程。

深度分析
Sentence Transformers在v5.4擴展到文字、影像、音訊與影片的多模態嵌入與重排序功能。新版可把不同模態映射到共用向量空間,支援跨模態相似度比較與混合模態重排序,適用於視覺文件檢索與多模態RAG流程。此更新簡化多模態檢索整合,但也提高訓練與部署的資源需求,推升相關微調與基礎設施工具的重要性。

深度分析
Sentence Transformers 在 2026 年 4 月推出 v5.4,加入多模態嵌入與重排功能,支援文字、影像、音訊與影片的統一向量化。透過模型自動偵測模態並使用相同相似度函式,開發者可實作跨模態檢索與混合模態重排。此更新預計加速視覺文件搜尋與多媒體 RAG 流程,提升 AI 應用的多樣性與效能。