深度分析
SMETA‑ZSL:結合大型語言模型與跨模態對齊的零樣本資安威脅分類突破
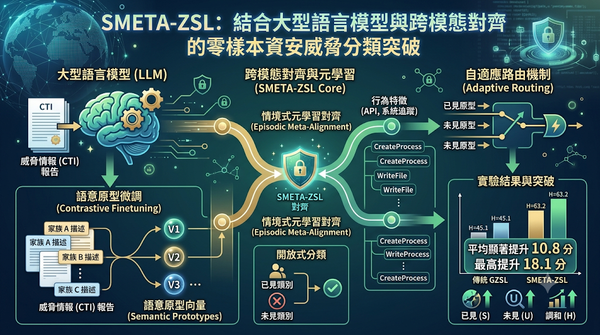
隨著新興惡意程式層出不窮,傳統防禦難以及時取得標記資料。研究提出 SMETA‑ZSL,透過對比微調的語言模型產生語意原型,並以情境式元學習對齊行為特徵,實現開放式零樣本威脅分類。實驗顯示在七項基準上平均顯著提升 10.8 分,最高可達 18.1 分。
深度分析
隨著新興惡意程式層出不窮,傳統防禦難以及時取得標記資料。研究提出 SMETA‑ZSL,透過對比微調的語言模型產生語意原型,並以情境式元學習對齊行為特徵,實現開放式零樣本威脅分類。實驗顯示在七項基準上平均顯著提升 10.8 分,最高可達 18.1 分。

深度分析
隨著時間序列分類需求激增,研究者提出InstructTime++以多模態語言模型結合離散化與隱含特徵抽取,提升分類精度並克服傳統模型在語意關聯與上下文整合上的限制。此框架同時引入統計特徵與視覺語言說明,將多視角隱含資訊文字化,與指令式生成流程結合,於基準測試中超越傳統CNN與Transformer。

深度分析
隨著AI生成影像快速成長,傳統僅關注失真指標已不足。研究提出MST‑CLIPIQA多尺度雙流框架,分別以粗粒度與細粒度CLIP編碼捕捉全局語意與局部紋理,並透過門控特徵融合自適應蒸餾。實驗顯示在五大基準上SRCC提升1.1%以上,且參數僅0.8M,顯示該技術在品質與效能上具顯著優勢。

深度分析
文字屬性圖(TAG)結合節點文本與結構資訊,ERAlign 以能量模型將 GNN 結構向量與 LLM 文本嵌入投射至共享空間,透過層級對齊與 Cramér 距離最小化降低表示漂移。實驗顯示在八個基準資料集上達到最佳表現,提升半監督與零樣本傳遞能力,同時具備高效訓練與可解釋性。

深度分析
本研究針對音樂串流的序列推薦問題,打造結合音訊、歌詞嵌入與LLM生成語意標註的多模態框架,並加入聆聽完成率作為行為信號。實驗在LastFM-1K資料集顯示,融合內容特徵後Recall提升至95%、NDCG提升至79%,同時指出簡單融合未必帶來加成,跨模態對齊仍具挑戰。

深度分析
研究探討點雲是否提升3D大語言模型的空間推理能力。作者以文字、影像與點雲相互替換輸入,並提出ScanReQA基準評估二元空間關係與絕對座標理解。實驗顯示純文字或影像輸入仍能取得競爭成績,模型對點雲注意力偏低且在細緻關係推理上表現有限,指出3D LLM在利用點雲結構座標進行精細推理上存在瓶頸。

深度分析
多模態數學推理受關注,但模型常誤讀圖示或對齊失誤,導致推理不一致。研究提出結構化感知、顯式對齊與可驗證推理的統合框架,改善中間步驟評估。此方向或重塑 AI 數學教育與應用格局。

InstrAct
隨著教學影片日益增多,細粒度動作辨識仍具挑戰。InstrAct 以資料過濾、硬負樣本與 Action Perceiver 抽取運動特徵,並加入 DTW 對齊與遮蔽動作建模輔助目標。實驗證明其在語意推理、程序邏輯與細粒度檢索上優於現有模型,提升影片動作理解。

跨模態對齊
研究聚焦於獨立預訓練的視覺與語言編碼器跨模態對齊,使用功能映射框架分析譜幾何。發現兩模型譜相似但特徵基底未對齊,對角占優度低且正交誤差高。此譜複雜度‑方向差距揭示跨模態對齊的結構限制。