
深度分析
利用 Gate‑Zero Growth 於 Transformer 實現零遺忘的增長與函數保留
隨著語言模型規模持續擴大,研究提出Gate‑ZeroGrowth以零門控方式在持續學習中保留函數。該方法透過零初始化門將新殘差塊加入模型,理論保證舊參數不變且新參數在成長點平坦。實驗顯示在300M→857MTransformer上幾乎零遺忘,優於未使用零門控的基線。
深度分析
隨著語言模型規模持續擴大,研究提出Gate‑ZeroGrowth以零門控方式在持續學習中保留函數。該方法透過零初始化門將新殘差塊加入模型,理論保證舊參數不變且新參數在成長點平坦。實驗顯示在300M→857MTransformer上幾乎零遺忘,優於未使用零門控的基線。

深度分析
隨著深偽技術快速演進,偵測模型面臨性能衰退問題。研究提出BitMindForensics,利用開放式激勵機制讓生成者與偵測者同步競賽,持續刷新訓練資料。實驗顯示其在多項公開基準上達到0.9以上AUC,並在時間序列測試中隨快照更新提升偵測力,預示未來偵測服務將更依賴動態資料流與經濟驅動的自適應流程。

速報
本研究重新檢視持續學習(Continual Learning, CL)的核心目標,指出過度追求知識保留可能阻礙在非靜態環境中的即時適應。

深度分析
隨著大型預訓練模型在多任務環境下的應用日增,舊任務資料往往無法取得,導致持續學習面臨遺忘問題。研究提出 PLATE(Plasticity‑Tunable Efficient Adapters),利用模型權重的冗餘性,同時構建受保護的更新子空間與限制更新於冗餘神經元,僅訓練低秩適配器參數。
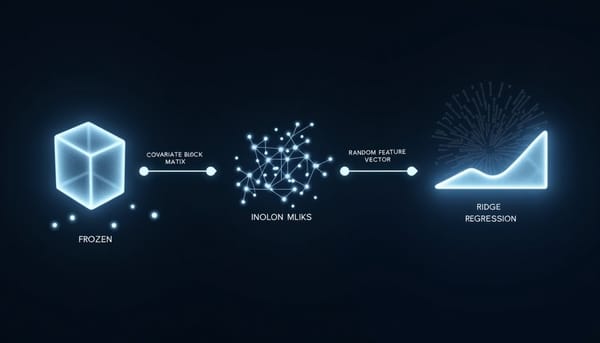
深度分析
隨著大型語言模型不斷推出,新型生成器的文字辨識成為挑戰。研究提出 RidgeFT,採用凍結編碼器、協方差校正與固定隨機特徵,僅以類別統計完成增量更新,免除舊資料重放。實驗在多主題、多模型設定下,全面提升 macro‑F1,兼顧舊類別保留與新類別適應。

深度分析
隨著多模態大型語言模型快速發展,研究多聚焦於靜態環境的效能上限,卻忽視真實職場的動態任務排程、主動探索與持續學習需求。作者提出 Trainee‑Bench,評測代理人在流式任務、資訊隱蔽與規則生成情境下的表現,實驗顯示現有 SOTA 代理人在探索與持續學習上仍有顯著缺口。

深度分析
隨著GDPR要求資料刪除,機器去學習成關鍵。研究提出Purge利用A‑GEM梯度投影,結合多層表示抹除與retain‑confusion目標,確保不提升保留損失。實驗在五個資料集上,保留精度維持96%以上,且會員推斷AUROC接近0.5,優於現有基線。

深度分析
隨著串流資料即時處理,傳統RNN與Transformer受限於回傳時間與窗口長度。研究提出SHARP框架,透過睡眠階段的加速回放將記憶層級化,顯著提升長程依賴保持與預測表現。在text8與PG-19基準測試中,SHARP相較於傳統遞迴模型在前向與回溯BPC上均有明顯下降,證明其有效延伸有效上下文窗。

速報
本研究探討深度神經網路在持續學習情境下為何會失去塑性,導致無法在不重新初始化參數的情況下學習新任務。作者發現,新任務初始化時會出現Hessian頻譜崩潰,意味著有意義的曲率方向消失,梯度下降失效。

深度分析
傳統深度模型在持續學習時常出現遺忘問題,同時對抗式擾動也能輕易改變預測,兩者缺一不可的防護需求長期未被同時解決。研究者提出 SHIELD,利用超網路產生任務專屬的權重向量,並將目標模型的輸入以區間形式傳遞,藉由區間立方體保證在指定範圍內的所有樣本皆得到相同預測,從而同時抑制遺忘與提升對抗魯棒性。

深度分析
城市交通預測長期受限於固定感測網路。EvoXXLTraffic將XXLTraffic重組為逐年演化的感測器集合、年度流量矩陣與圖結構快照,並提出以年為單位的串流預測協議。基準測試發現多數現行頂尖模型在演化資料上表現退化,且冷啟動感測器成為主要瓶頸。

深度分析
為即時 AR/VR 與機器人應用,系統需在裝置端邊學習新的人類動作且不遺忘既有類別。CLANE 在 Intel Loihi 2 上結合事件相機、脈衝卷積網路與擴展 CLP-SNN,並以時間聚合與定點正規化處理動作片段。整合式部署在晶片上完成推論與在線增量學習。於 THU E‑ACT‑50 評估顯示,在僅小幅準確度下降下,實現顯著能耗與延遲改善。