速報
廣播過程合成語言:上下文長度與自回歸推理的界限
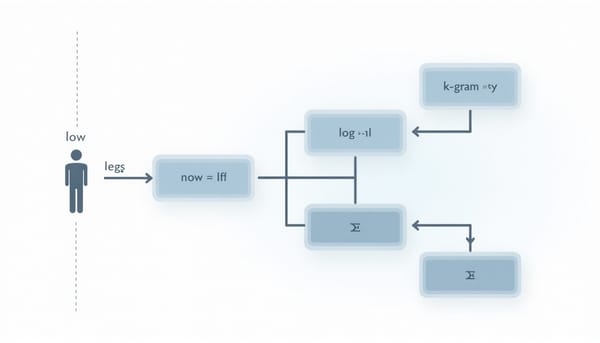
利用樹狀廣播過程的合成語言檢驗上下文與推理。在精確k-gram假設下推導生成序列分布。發現:硬約束著色語言在有限上下文下會產生非法樣本,忠實抽樣需Ω(n)上下文;具推理的自回歸模型以Θ(logn)工作記憶可精確抽樣。實驗以變換器訓練結果驗證了理論預測。
速報
利用樹狀廣播過程的合成語言檢驗上下文與推理。在精確k-gram假設下推導生成序列分布。發現:硬約束著色語言在有限上下文下會產生非法樣本,忠實抽樣需Ω(n)上下文;具推理的自回歸模型以Θ(logn)工作記憶可精確抽樣。實驗以變換器訓練結果驗證了理論預測。
速報
研究團隊針對大型語言模型(LLM)在同時處理多份文件或多筆實例時的表現做全面評估。雖然模型在單一任務上通常表現良好,但在多實例情境中會先出現小幅效能下降(約20到100筆實例),隨著實例數再增加則出現明顯崩潰。分析指出,上下文長度與效能衰退相關,但實例數對最終表現影響更強;