
深度分析
Vector-Bench 評估:AI 模型 SVG 編輯精確度僅 2.35%,修復與保留難兩全
Vector-Bench 是一個針對 SVG 指令式編輯的嚴謹基準測試,包含 40 個修復任務,每個任務配對一個損壞的 SVG 程式碼與作者撰寫的視覺指令、隱藏的目標程式碼、平均 5.05 個註釋修復和 60.55 個保護物件。指令僅描述可見缺陷,不暴露元素識別碼、座標、顏色碼或路徑資料。
深度分析
Vector-Bench 是一個針對 SVG 指令式編輯的嚴謹基準測試,包含 40 個修復任務,每個任務配對一個損壞的 SVG 程式碼與作者撰寫的視覺指令、隱藏的目標程式碼、平均 5.05 個註釋修復和 60.55 個保護物件。指令僅描述可見缺陷,不暴露元素識別碼、座標、顏色碼或路徑資料。
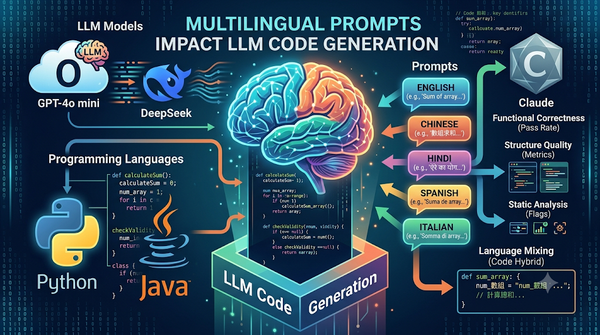
速報
研究探討不同語言提示對大型語言模型程式碼生成的影響,將 460 個 Python 與 Java 任務的英文提示翻譯成四種語言,測試 GPT‑4o mini、DeepSeek、Claude。結果顯示英文提示未必最佳,語言影響視程式語言與模型而定,生成程式碼常混用英語與提示語言。

深度分析
研究以執行驗證方式比較四大前沿 AI 教師,發現模仿訓練未提升程式碼學生,反而以可驗證獎勵的強化學習提升表現,顯示教師合作應聚焦於環境建構。在硬體成本與模型版權爭議下,此研究提供可復現的本地化管線,對開發者與產業具參考價值。此結果也暗示未來 AI 教師的合作模式可能重塑開源社群與商業授權的平衡。

深度分析
隨著大型語言模型生成程式碼的普及,研究者提出「實證計算」概念,透過自然語言提示直接求解問題,結果以最可能正確為依據。實驗顯示在排序與子集和等任務上可達近乎正確,相較於傳統程式化流程,實證計算免除格式合約,提供更彈性但亦帶來正確性不確定性,預計將推動AI工具安全基礎設施的重新設計。

深度分析
JetBrains 於 2026 年 6 月正式發佈 Mellum2,一款 12 B 參數的 Mixture‑of‑Experts(MoE)模型,採用每個 token 只啟動約 2.5 B 參數的設計,使推理速度比同規模開源模型提升逾兩倍,並以 Apache 2.0 授權釋出。該模型聚焦文字與程式碼工作負載,適用於路由、檢索增強生成(RAG)與私有部署等高頻 AI 任務,為開發者提供更快且可自行管理的選項。

Ponytail
Ponytail是一個讓AI代理以最簡潔方式產出程式碼的開源工具,支援16種代理,測試顯示可減少約54%以上的程式碼量,成本下降20%,速度提升27%,同時保持安全防護。在GitHub上已獲得超過69000顆星,且適用於Claude、Cursor等多種大型語言模型,為開發者提供一行解決方案的懶人選項。

深度分析
研究探討在多代理大型語言模型團隊中,透過高低親和力個性提示,對結構化程式碼、開放式研究與競爭議價三種任務的表現差異。結果顯示,程式碼任務因格式限制對績效影響有限,然而在研究與議價任務中,低親和力顯著降低里程碑完成度,說明任務結構是個性組成效應的關鍵調節因素。

深度分析
研究以競程平台 UOJ 為基礎,推出 UOJ‑Bench 評測大型語言模型的程式碼生成、破解與修復能力。測試顯示即使單次推論模型仍無法發現超過半數錯誤;透過測試時間擴展可提升至 90% 以上,但計算成本高。此結果暗示 LLM 可成為判題系統的輔助工具,需權衡效能與資源。

速報
ArXiv發表LagunaM.1與LagunaXS.2,兩款為長程代理式編碼設計的MoE基礎模型。作者說明在稱為ModelFactory的系統中從頭訓練與量化;M.1與XS.2在軟體工程與終端機基準上與同級開源模型相當,XS.2權重已以Apache2.0釋出。

深度分析
在軟體工程領域,大規模語言模型被用於自動產生可執行程式碼。本綜述整合30篇次級研究,採HELM框架評估準確性、健壯性與效率,並檢視整合挑戰如經濟可行性與評估有效性。結果顯示基準表現普遍良好但實務泛化與整合仍有限,建議優先推動領域感知模型與標準化評估。
深度分析
資料前處理長期是資料分析中的時間瓶頸。

深度分析
研究以受限於小型程式模型的實務者為出發,提出SketchVerify:列舉多種演算法策略、生成帶空洞的程式草圖並多次填充、執行驗證與指紋聚類選出候選。實驗顯示在困難題子集內,SketchVerify於相同候選數下優於平坦抽樣,但無法取代升級至更強模型。