
速報
IPO Finance Agent:結合長文件檢索的金融模型新基準
Finance Agent v2 只適用於 SEC 定期報告,處理 IPO S‑1 文件時因篇幅過長失效。研究者以上下文檢索與自動評分管線擴充模型,推出 IPO Finance Agent,並以 Qwen 3.7 Max 取得 79.4% 準確率,成本僅 0.30 美元,顯著優於既有基準。
速報
Finance Agent v2 只適用於 SEC 定期報告,處理 IPO S‑1 文件時因篇幅過長失效。研究者以上下文檢索與自動評分管線擴充模型,推出 IPO Finance Agent,並以 Qwen 3.7 Max 取得 79.4% 準確率,成本僅 0.30 美元,顯著優於既有基準。

速報
研究提出 CARE(Co-occurring Associated REtained concepts)概念,針對擴散模型的去除(unlearning)任務,避免同時刪除無害的共現概念。作者設計 CARE 分數作為衡量指標,並開發 ReCARE 框架,能自動構建包含目標圖像中良性共現詞彙的 CARE 集,在訓練過程中保護這些概念。

速報
研究探討新興錯位(EM)與模型角色失衡的關聯,提出以自我產生文字辨識(SGTR)為核心的微調方法,作為針對角色的防禦手段。實驗在 GPT-4.1、Qwen2.5-32B-Instruct 與 Seed-OSS-36B-Instruct 三款大型語言模型上,使用多套 EM 資料集,與正向微調基線(領域資料、通用知識、詞彙計數)比較。

速報
本研究探討在自然語言處理中,將多種預訓練目標同時應用於編碼器‑解碼器模型,對生成與問答任務的影響。作者提出「Match Task to Objective (MTO)」框架,能自動匹配任務與最適目標,並在預訓練與微調階段使用相符的模板。實驗顯示,在少樣本設定下,該方法相較傳統基線提升逾120%,在全資料集上亦保持領先。

速報
深度學習大規模訓練的瓶頸在系統實作。BluTrain 以純 C++/CUDA 建構原生張量與自動微分模組,並加入分散執行與 MLIR 編譯器。實測在 8 顆 RTX 6000 Ada GPU 上,吞吐量 407K token/s、記憶體減少 22%,驗證損失略低於 PyTorch,顯示效能與資源利用雙贏。

速報
將大型語言模型的工具使用能力濃縮至小型模型是落地應用的關鍵。傳統的監督微調因過度對齊教師軌跡,導致跨領域表現不佳;而強化學習在模型容量受限時,稀疏回饋或嚴格軌跡匹配都會出現困境。研究提出 MENTOR,採用彈性且具流程感知的獎勵機制,以教師參考而非嚴格複製指導模型行為,兼顧行為對齊與下游效能。

速報
在數位環境日益複雜的情境下,確保 AI 代理人的安全已成為迫切需求。傳統的執行時監控多以 Datalog 形式的確定性政策為基礎,無法處理具備失敗機率的模糊判斷或狀態轉換。研究團隊提出一套基於分佈式魯棒最佳化的驗證框架,能在不假設預測子獨立性的前提下,計算政策違規機率的上界。

速報
Style‑content 雙參考生成旨在同時保留內容語意與套用風格,然而缺乏大量內容‑風格分離且涵蓋長尾風格的三元組資料,使得模型在內容忠實、風格對齊與指令遵循間難以取得平衡。研究提出 FreeStyle,透過社群 LoRA 挖掘作為風格與內容的組合錨點,建立嚴謹的生成與過濾流程,產出跨多模型的大規模風格參考與內容參考三元組。

速報
本研究提出一套通用框架,用以分析多代理系統中代理行動與集體觀測之間的回饋迴路。核心以「力量」與「回應函數」兩個代理層級變數為基礎,推導出包括總力量、有效力量、熵、秩序、脆弱度與流動性等宏觀特性。研究進一步引入風險偏好係數的系統效用函數,探討成長與韌性之間的平衡,指出過度同步雖能提升產出,卻可能增加系統脆弱性並降低流動性。

速報
近期大型語言模型(LLM)在自動作文評分(AES)領域取得突破,但其內部運作仍不明朗。研究者系統性分析了八種 LLM 在兩個英語作文資料集(ASAP++、CSEE)與一個葡萄牙語資料集(ENEM)上的隱藏表示,使用線性探測、跨提示泛化、維度縮減與神經元層級分析。

速報
目前機器學習模型大多以預測精度作為唯一評估標準,卻忽略了模型輸出是否遵守既定的邏輯或領域規則。研究團隊提出 Rule Violation Score(RVS)作為補充指標,能獨立於預測準確度量測模型對硬性規則與軟性規則的遵守程度。
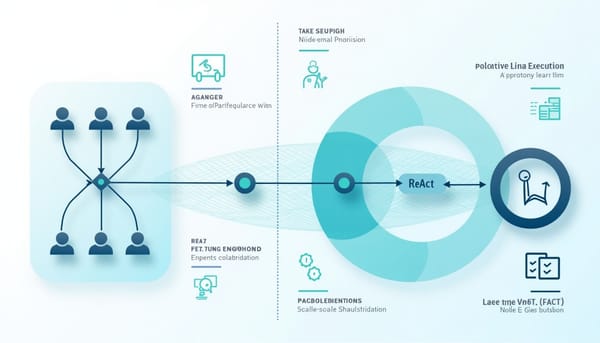
速報
企業 AI 需要持續監控與自動化。研究比較 DAG Plan and Execute 與 ReAct 兩種多代理架構,測試 208 個情境跨小至全企業規模。結果顯示規模是主要瓶頸,DAG 在小規模精度高,ReAct 更具彈性;任務管理器可大幅降低延遲並提升事件正確率。