
速報
大型語言模型人工群聚:以LLM模擬群體智慧降低估算誤差
研究團隊以 960 筆手動提示,測試三款商業大型語言模型(GPT‑5、Gemini 2.5 Pro、Claude Sonnet 4.5)在八項估算任務中的內部抽樣與跨模型聚合效應。
速報
研究團隊以 960 筆手動提示,測試三款商業大型語言模型(GPT‑5、Gemini 2.5 Pro、Claude Sonnet 4.5)在八項估算任務中的內部抽樣與跨模型聚合效應。

速報
形式規格提供數學嚴謹性與表達力,可直接指定目標與限制,並定義達成策略。研究將此概念引入部分可觀測的多代理強化學習(MARL),提出 HyPOLE 框架,利用 HyperLTL 形式規格引導學習,並結合集中訓練分散執行(CTDE)技術合成分散策略。
速報
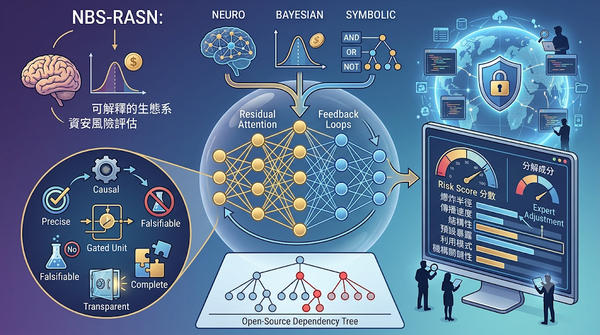
研究團隊提出 Neuro‑Bayesian‑Symbolic Residual Attention Shallow Network(NBS‑RASN),一種結合神經網路、貝葉斯推理與符號推理的淺層架構,用於開源軟體生態系的資安風險評估。
速報
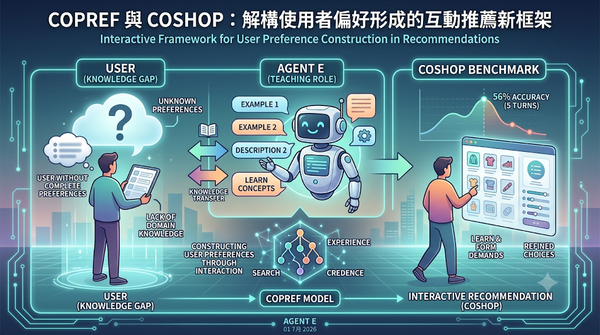
本研究挑戰傳統代理人假設使用者具備完整偏好,指出多數使用者缺乏領域知識,無法直接回答偏好問題。作者以資訊經濟學的搜尋‑體驗‑可信度模型為基礎,提出 CoPref 模型,說明使用者如何在代理人對話中逐步建構偏好。隨後設計 CoShop 基準,讓代理人在互動式推薦情境下協助使用者學習並形成需求。

速報
研究團隊推出 StarDojo,利用《星露谷物語》打造的開放式模擬環境,針對 AI 代理人在農耕、製作、探索、戰鬥與社交五大領域的生產與生活技能進行綜合評估。基準提供 1,000 項精選任務與 100 �項精簡子集,支援無鍵鼠介面、跨平台與多實例平行執行,適合測試以多模態大型語言模型(MLLM)為基礎的先進代理人。
速報
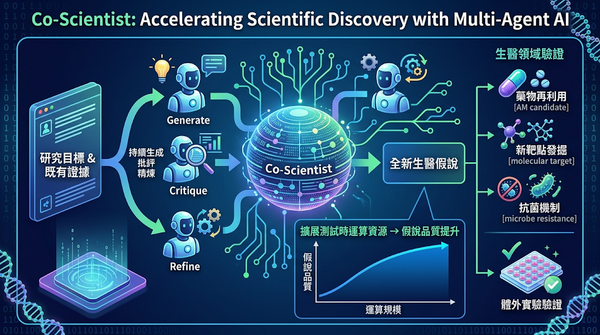
科學發現依賴研究人員提出新假說並經過嚴謹驗證。為提升此流程,研究團隊開發了 Co‑Scientist,一套以 Gemini 為基礎的多代理 AI 系統,專注於結構化科學思考與假說產生。系統在研究目標與既有證據的條件下,持續生成、批評與精煉假說,並透過擴展測試時運算資源提升品質。
速報
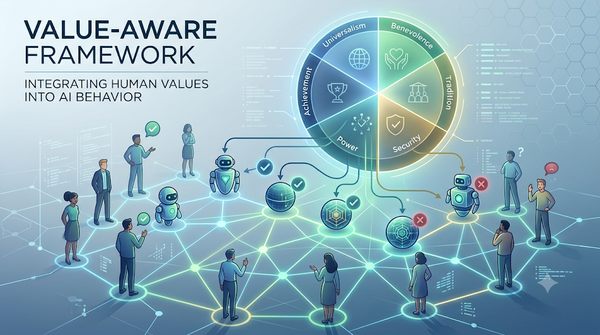
本研究針對 AI 系統在與人類互動時的價值對齊問題,提出一套正式的計算框架,用以在多代理環境中表示與推理人類價值。作者以社會心理學對價值關係與重要性的研究為基礎,建構出能捕捉價值關聯、重要度與計算語意的模型,並示範在真實情境下評估代理行為的價值對齊程度。

速報
研究團隊系統性探討大型語言模型(LLM)在自動化程式碼漏洞偵測時,是否會受到與人類相同的認知啟發式影響。透過控制實驗,僅改變程式碼周圍的文字敘述,分別觸發光環效應、框架效應與錨定效應,並在三種程式語言上測試八種 LLM。結果顯示所有模型皆會受此三種啟發式影響,框架效應的平均易感度最高達 33.2%。
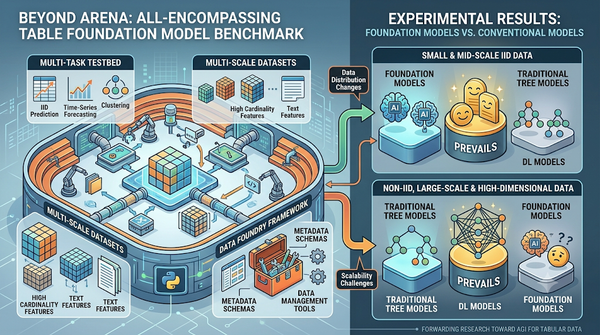
速報
表格基礎模型評測散見各處,研究團隊推出 BeyondArena 整合多任務與多規模資料集,並以 Data Foundry 框架統一管理。測試結果顯示,現有模型在小型 IID 資料表現佳,卻在非 IID、大規模或高維度情境下仍被傳統樹模型領先,凸顯未來研究方向。
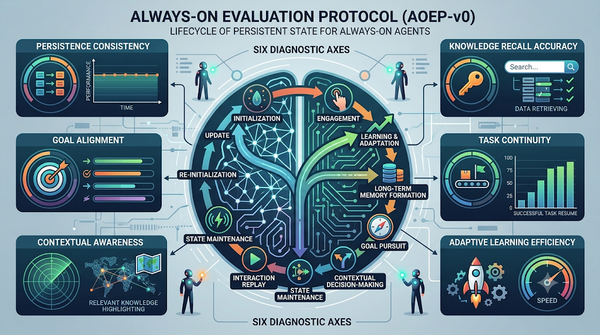
速報
本篇調查聚焦於永續運作的代理人(always‑on agents),這類系統會在多次互動中累積持久狀態,包括記憶、任務帳本、權限、憑證、承諾、來源與稽核紀錄等。研究以六大診斷軸(權限、範圍、可變性、來源、可復原性、可行動性)檢視文獻,並追蹤狀態的寫入、驗證、組織、檢索、執行、更新、遺忘、稽核與回滾等生命週期。
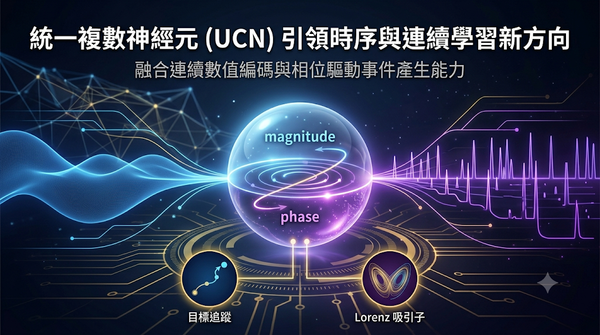
速報
研究針對同時需要連續值編碼與時序動態的問題,提出統一複數神經元模型,以幅度表示訊號強度、相位控制時間演化與脈衝發射。結合 BP 與 BPTT 的訓練框架,並加入事件驅動相位學習規則降低運算成本。實驗證明模型在目標追蹤與混沌系統學習上表現穩定且具解釋性,適用於神經形態與邊緣 AI 應用。
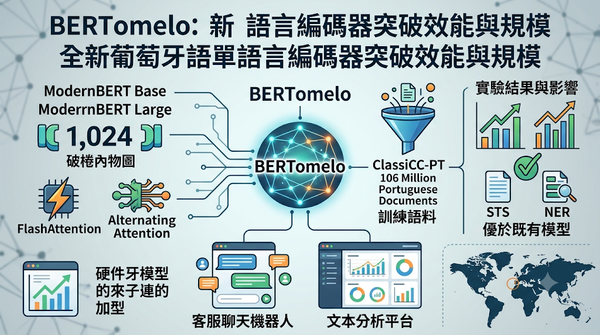
速報
隨著編碼器成為多項 NLP 任務的主流,葡萄牙語單語言模型仍落後於最新架構。BERTomelo 以 ModernBERT 為基礎,支援 1,024 token 視窗並加入 FlashAttention 與交替注意力機制,於 1.06 億篇語料上訓練。測試顯示其在 STS 與 NER 等任務上優於既有模型,且效能更佳。