
速報
QuITE:以 Query Token 解決不規則多變量時間序列嵌入問題
不規則多變量時間序列在實務常見但抽樣不均使建模複雜化。QuITE以可學習的querytokens透過單層自注意力聚合不規則觀測,產生直接可供既有多變量時間序列骨幹使用的潛在表示,無需插值或改動架構。實驗顯示在預測與分類任務上帶來整體實質提升。
速報
不規則多變量時間序列在實務常見但抽樣不均使建模複雜化。QuITE以可學習的querytokens透過單層自注意力聚合不規則觀測,產生直接可供既有多變量時間序列骨幹使用的潛在表示,無需插值或改動架構。實驗顯示在預測與分類任務上帶來整體實質提升。

速報
大型語言模型在微調過程中常會喪失原本的安全對齊,且攻擊者可透過有害微調移除防護並誘發不安全行為。為此,研究提出SPARD,一個將安全投影交替優化(SPAG)與關聯-多樣性資料選取結合的防禦框架。SPAG透過在效用更新與以安全資料為基準的顯式投影間交替,將模型約束回安全域;

速報
本文提出一種改良的擴散後驗取樣方法,將傳統以手動標量調整的資料一致性指引,替換為每個雜訊層的阻尼高斯牛頓校正。該校正於擴散態座標運算,將測量似然梯度回傳至去噪器,採用單側曲率模型以避免前向去噪雅可比,並引入與去噪殘差對齊的秩一阻尼以抑制不穩定。

速報
研究以視覺語言模型(VLM)檢視史料OCR表現。採用受控影像擾動與逐詞分級判定,發現多數VLM即使文字流暢也可能不以視覺為依據,錯誤具語言先驗傾向;專用OCR與通用VLM在視覺依賴上差異明顯,解碼時修正效果有限,後處理語言模型能部分補救。具有實務意涵

速報
研究評估以辯論作為可擴展監督在程式可驗證任務的效用。採用提案者—評論者架構,假定辯論者較強、裁判較弱。當評論者分類能力顯著優於裁判,且裁判把評論視為需驗證的主張時,辯論優於諮詢;能力接近則效用不顯著或降低驗證率。研究亦發現去除反駁輪次不削弱效益,一次獨立評論可回收多數好處。

速報
一項以147074篇PLoS與Nature系列論文為基礎的研究指出,人工智慧輔助寫作,特別是大型語言模型的應用,正在改變學術寫作與研究團隊組成。研究採用多種迴歸分析、Poisson與傾向分數配對等方法檢驗相關性,發現使用AI輔寫的團隊傾向年輕且規模較小,但並未因此降低科研影響力;

速報
代理人能力提升導致既有基準飽和且新題昂貴。TASTE以工具序列反向合成任務,結合自適應對比n-gram與大型語言模型驗證,經群聚挑選與難度迭代生成高覆蓋基準。11組模型測試顯示舊基準接近飽和的模型在新任務上表現顯著下滑,工具組合數量亦超過翻倍。

速報
不少人工智慧評估只在實驗室測試,難以反映低資源環境的真實表現。本研究主張把「部署系統」而非單一模型作為評估單位,並整合雜訊輸入、語碼混用、斷線、低端硬體與領域轉移等部署條件。提出共享報告框架,強調可比較且具部署敏感性的報告格式。並建議提供簡潔一頁基準卡與部署檔案以利決策。
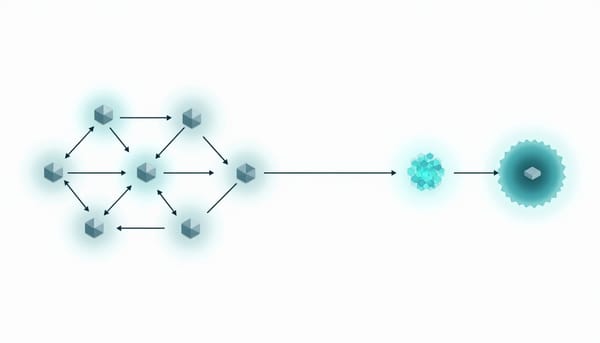
速報
在記憶受限的啟發式搜尋場景,研究提出GONDOR,一種基於貪婪優先搜尋的記憶節省延伸。它週期性壓縮搜尋樹並保留稀疏錨點,再於達到目標時透過錨點間重搜尋還原路徑。此外實驗顯示在低記憶預算下能提升覆蓋率,並提供含布隆過濾器的實作以促進後續研究。
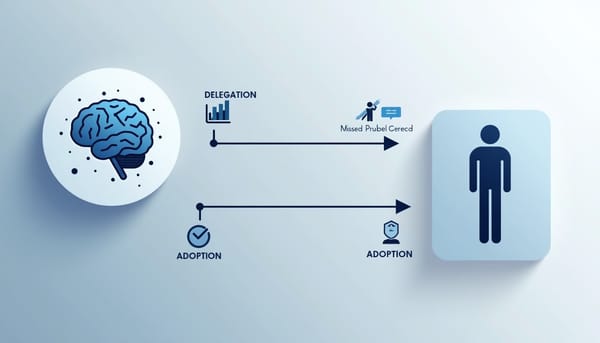
速報
研究聚焦人類在與人工智慧協作時如何做出信賴決策,將行為分為委託(讓系統自主行動)與採納(評估系統建議)兩類。研究在問答競賽中,將 23 位專家與 16 個 AI 代理配對,蒐集 387 次委託決策與 1440 次採納決策。

速報
學術論文常以圖示說明複雜方法。提出DiagramRAG透過檢索增強把草圖與相容參考結合以補全圖示。技術用知識圖譜與嵌入對齊草圖與圖示。實驗在DiagramBank與FigureBench分別達到F1分數0.848與0.802,並改善生成品質與推論延遲。

速報
自主與代理型人工智慧在實際場域放大後,幻覺與不當持續行為成為挑戰。論文提出 SMARt 管理型自治框架,定義偵測認知漂移、暫停推理、嘗試恢復與放棄控制等行為,並以帶時限的受護 Petri 網給出形式化守則,主張把失敗管理納入自治生命週期以提升可治理性。研究也討論場域觸發集合的適配與安全擴展。