
速報
EngGPT2MoE-16B-A3B:以混合專家架構推進義大利語大型語言模型表現
報告評估義大利ENGINEERING的EngGPT2MoE-16B-A3B,為16B參數MoE且在任意時刻啟用3B活躍參數。研究以多項國際與義大利基準比較模型表現,結果顯示該模型在多數國際測試優於或等同主要義大利模型,且在RULER32k長上下文設定取得最佳成績。
速報
報告評估義大利ENGINEERING的EngGPT2MoE-16B-A3B,為16B參數MoE且在任意時刻啟用3B活躍參數。研究以多項國際與義大利基準比較模型表現,結果顯示該模型在多數國際測試優於或等同主要義大利模型,且在RULER32k長上下文設定取得最佳成績。

深度分析
一個名為 AI IQ 的專案把超過 50 款前沿大型語言模型,依 12 項基準分成抽象、數學、程式與學術四大維度,並進一步推導出綜合 IQ 分數。該網站同時納入情緒智商(EQ)評估與「有效成本」指標,並以鐘形分佈、散點與 3D 視覺化呈現結果。支持者指出,這種單一框架讓企業採購和模型路由決策更易理解;
速報
工業設備監控仰賴工程師撰寫的符號規則,但瓶頸在於把規則翻譯成具體維修步驟。研究建立一個標準化基準,含6,690道專家驗證多選題、118組規則—動作配對與16類設備,並實作將規則正規化為析取標準式、用嵌入抽樣生成干擾選項的symbolic-to-MCQA流程,設計五種變體以探查失效模式。
深度分析
隨著大型語言模型在推理與工具整合上的突破,研究團隊推出 ChinaTravel 基準,針對中文多點旅遊規劃收集真實需求,並以領域專屬語言測試可行性與偏好滿足度。實驗顯示神經符號代理人在約 28% 的約束滿足率上遠超純神經模型的 2.6%。研究亦指出開放式語言推理與未見概念組合是未來主要瓶頸。
速報
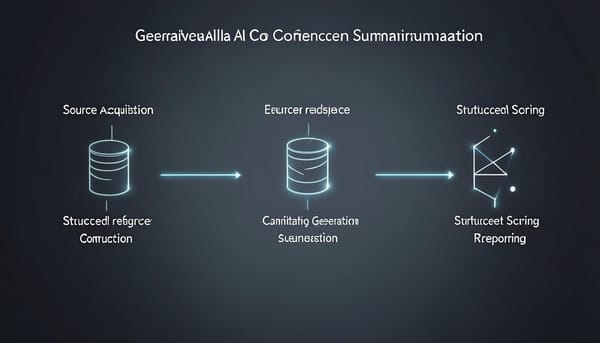
研究團隊提出一套可重用的生成式人工智慧評估管線,並針對會議摘要場景釋出公開套件。系統將評估流程拆成五個階段:來源擷取、結構化參考建構、候選生成、結構化評分與報告,並把參考與評估輸出當作帶類型的持久化資產,方便彙總、議題分析與統計檢驗。

大佬動態
Simon Willison 指出 GPT‑5.5 已透過 OpenAI Codex 可用並向付費 ChatGPT 推播;他預覽後稱模型反應快速且能依指令構建結果,但 API 尚未全面開放,OpenAI 正與夥伴協作處理部署與安全,短期內會將 GPT‑5.5 帶上 API,這將影響基準測試與開發者可重現性。