深度分析
REDDIT:解決 ASR 模型時間戳漂移的輕量化後訓練框架
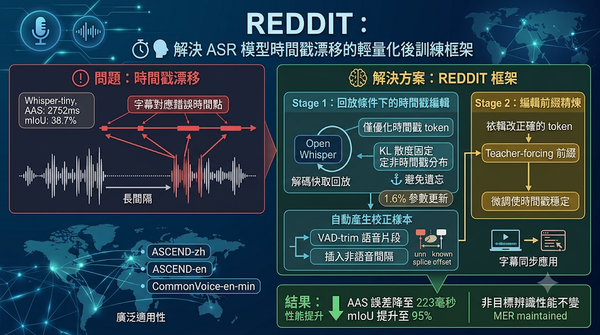
自動語音辨識系統在長時間靜音間隔後會出現時間戳漂移,導致文字內容雖正確卻對應錯誤時間點。研究提出REDDIT兩階段後訓練框架,利用模型自我回放編輯時間戳,同時凍結非時間戳分布以防遺忘。實驗顯示在Whisper‑tiny上,長間隔mIoU提升至95%,AAS誤差降至223毫秒,且非目標辨識性能保持不變。
深度分析
自動語音辨識系統在長時間靜音間隔後會出現時間戳漂移,導致文字內容雖正確卻對應錯誤時間點。研究提出REDDIT兩階段後訓練框架,利用模型自我回放編輯時間戳,同時凍結非時間戳分布以防遺忘。實驗顯示在Whisper‑tiny上,長間隔mIoU提升至95%,AAS誤差降至223毫秒,且非目標辨識性能保持不變。

深度分析
隨著語音成為AI主要介面,Hume推出的RealWorldVoiceEQ以百萬級人類評分測試超過40種語音模型,聚焦語調、情緒與說話者身份等人類感知指標,發現現有基準普遍高估實際表現,凸顯需以新測量層提升商業應用可靠度。此結果促使業界重新思考模型訓練與部署策略,並加速人類回饋迴路的整合。

深度分析
研究指出自動語音辨識模型在長時間非語音段落會出現時間戳漂移。提出REDDIT兩階段重播分布編輯方法,利用自動生成的校正資料修正時間戳,同時避免遺忘問題。實驗顯示在Whisper‑tiny上將長段mIoU提升至95%。此方法僅更新0.6%參數,無需額外對齊模組,提升實務部署的可靠性。

深度分析
研究指出,隨著 Whisper 系列模型規模放大,幻覺現象會由訊號散佈轉為吸引子動態。透過光譜感受度定理與光譜傳播不穩定框架,分析跨注意力與自注意力的特徵譜變化。結果顯示,小型模型出現結構解體,大型模型則進入壓縮吸引子狀態,對未來語音辨識安全性提出警示。

FunASR
FunASR 是一個開源的工業級語音辨識工具箱,主打高速與多語支援,宣稱比 Whisper 快約 170 倍,支援超過 50 種語言。專案將端對端語音辨識與語者分離、情緒偵測、語音活動偵測等功能整合,並提供流式辨識與 OpenAI 相容的 API,方便在產業環境中部署與整合。

深度分析
近年大型語言模型(LLM)越獄攻擊研究習慣以「單一組態的攻擊成功率(ASR)」作為績效指標,但這種做法忽略了攻擊家族內部多個參數變體所帶來的覆蓋差異。本文介紹兩項補充指標:變異敏感度(VSM)與聯合覆蓋率(UC),前者量化最佳單一 ASR 與變體平均 ASR 的差距,後者衡量所有測試組態合併後能觸發不安全回應的提示比例。
深度分析
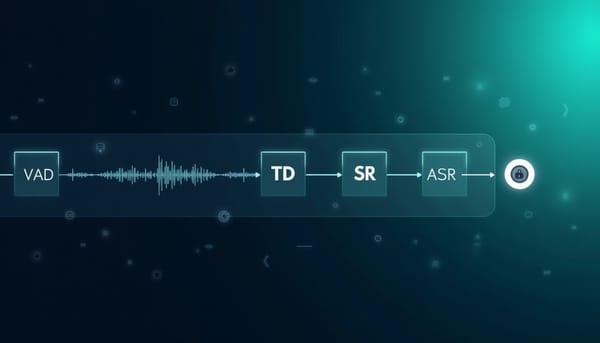
面對半雙工語音系統中級聯前端帶來的延遲與誤差累積,研究提出 UAF 統一音訊前端 LLM。此模型將 VAD、TD、SR、ASR 與 QA 都轉為自回歸序列預測,並以參考語音提示鎖定目標說話者,分段處理串流音訊。實驗顯示 UAF 在多項前端任務上達到領先表現,並能提升中斷偵測與回應時效,助於更自然的全雙工對話。