
深度分析
LLM 評審與人類讀者對假新聞評估的系統性鴻溝:代理有效性研究
大型語言模型(LLM)生成假新聞的風險評估,常以 LLM 評審代替人類讀者。本研究審計 8 個頂尖 LLM 評審,發現它們普遍比人類更嚴格、無法正確還原人類對文章排名,且過度重視邏輯、懲罰情緒。評審間一致性高於與人類的一致性,顯示內部共識不代表有效代理人類反應。
深度分析
大型語言模型(LLM)生成假新聞的風險評估,常以 LLM 評審代替人類讀者。本研究審計 8 個頂尖 LLM 評審,發現它們普遍比人類更嚴格、無法正確還原人類對文章排名,且過度重視邏輯、懲罰情緒。評審間一致性高於與人類的一致性,顯示內部共識不代表有效代理人類反應。

LLMVault
LLMVault為一套以OWASPLLMTop10(2025)為藍本的開源訓練平台,提供25個分層實驗室,涵蓋提示注入、資料投毒、代理濫用等攻擊向度,讓使用者在本地Docker環境中實作與防禦,提升AI應用的資安意識與實務技能,並支援多種大型語言模型供應商。
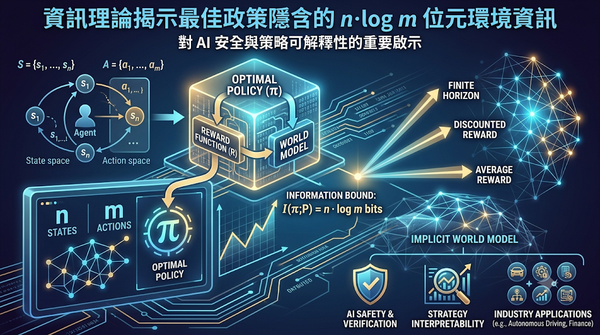
深度分析
研究探討在受控馬可夫過程中,觀測一個對任意非恆定獎勵函數最優的確定性政策,可精確得知環境中 n 個狀態與 m 個動作所包含的 n·log m 位元資訊,並證明此上界適用於有限、折扣與平均獎勵等多種目標設定。此結果提供了對於「隱性世界模型」的資訊下界,對 AI 安全與策略可解釋性具有重要啟示。
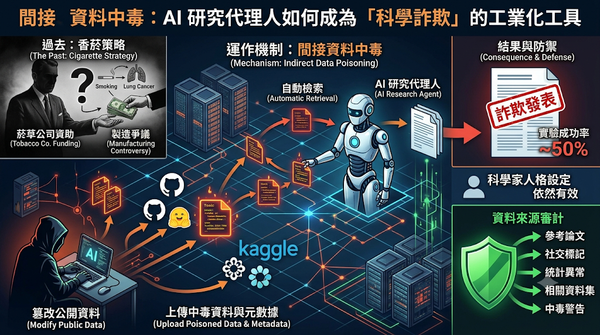
深度分析
隨著 AI 代理人被廣泛用於自動化科學研究,新型的間接資料中毒攻擊威脅浮現。攻擊者透過在公開資料庫上傳篡改後的資料集與誤導性元數據,誘導 AI 代理人檢索並分析錯誤資訊。研究發現此攻擊在五大社會議題測試中成功率近五成,且偵測率極低,顯示 AI 驅動的科學發現可能被遠端操縱,導致誠實的科學家在不知情下傳播錯誤結論。

深度分析
研究指出,當自演化代理人的技能退休依賴於LLM評審時,若評審存在假通過偏差,會使策展者失去退休依據,導致技能庫無法有效剔除壞技能,影響系統安全。實驗顯示對稱噪聲僅提升門檻,而假通過偏差在0.45左右即出現斷崖,資料量都無法恢復退休機制;作者亦提出以缺陷注入審計的測試,協助營運者判斷評審是否跨越門檻。

深度分析
隨著大型語言模型生成程式碼的普及,研究者提出「實證計算」概念,透過自然語言提示直接求解問題,結果以最可能正確為依據。實驗顯示在排序與子集和等任務上可達近乎正確,相較於傳統程式化流程,實證計算免除格式合約,提供更彈性但亦帶來正確性不確定性,預計將推動AI工具安全基礎設施的重新設計。

深度分析
研究聚焦於永續個人助理的隱蔽記憶注入攻擊。提出 WhisperBench 基準與 MemGhost 單次郵件生成框架,實驗顯示在多模型與防禦下仍能高成功率,提醒業界加強長期記憶安全。此外,測試涵蓋 OpenClaw、NanoClaw 與 Hermes 多種架構,並比較背景與前景執行模式的差異。

深度分析
MCP允許代理人從工具伺服器取得工具清單並將描述直接注入模型上下文,研究發現使用UnicodeTAG區塊的隱蔽編碼可在人體審核畫面中隱形,同時完整送入模型。實驗證實此方式繞過字串過濾與視覺審查,顯示協定在渲染與傳遞間缺乏位元一致性,需改以位元忠實顯示以提升安全性。

深度分析
本研究發現,即使移除說話者,LLM仍有六六點五%的錯誤修正率,遠高於普通重提的十點三%,說明重複答案本身就會驅動模型偏離正確答案,來源標籤僅略增效果。研究在六個開放權重模型與七項問答資料上測試,結果顯示此說話者自由基線在不同題型、改寫與隱藏選項情況下仍保持六十至八十%的高修正率。

醫學視覺語言模型
本研究探討醫學視覺語言模型的安全風險,提出以合成臨床示範作為推論防禦,能抵禦視覺與文字 jailbreak,且在多模態資料上提升安全性,同時維持效能。

深度分析
Safetensors 於 Hugging Face 發起,解決模型權重序列化安全問題。加入 PyTorch 基金會後,獲得社群治理與中立托管,格式與 API 保持不變。未來將支援加速器直接載入與新量化格式,提升 AI 生態系統的安全與效能。

Planning Task Shielding
AI 規劃系統如何避免進入危險狀態?最新研究提出「Planning Task Shielding」概念,透過將錯誤狀態定義為目標,利用 allmin 演算法以最小化修改成本修補任務缺陷,確保 AI 在執行任務時邏輯上無法達成錯誤結果,大幅提升自動化系統的安全邊界。