PEEK:為長期上下文的 LLM 代理打造可重用的上下文地圖
研究指出大型語言模型代理常需面對重複且龐大的外部上下文。PEEK以一個常數大小的上下文地圖快取定向知識,由Distiller、Cartographer與優先驅逐器維護,能在固定token預算下持續更新。實驗顯示PEEK在推理與學習任務中改進準確度並顯著降低迭代與成本。
要點速覽
面對重複且長期的外部上下文,PEEK 將可重用的「定向知識」緊湊地保存在提示中的上下文地圖,讓代理在後續呼叫時能快速取得核心背景與組織結構,提升查詢與推理效率。
方法概述
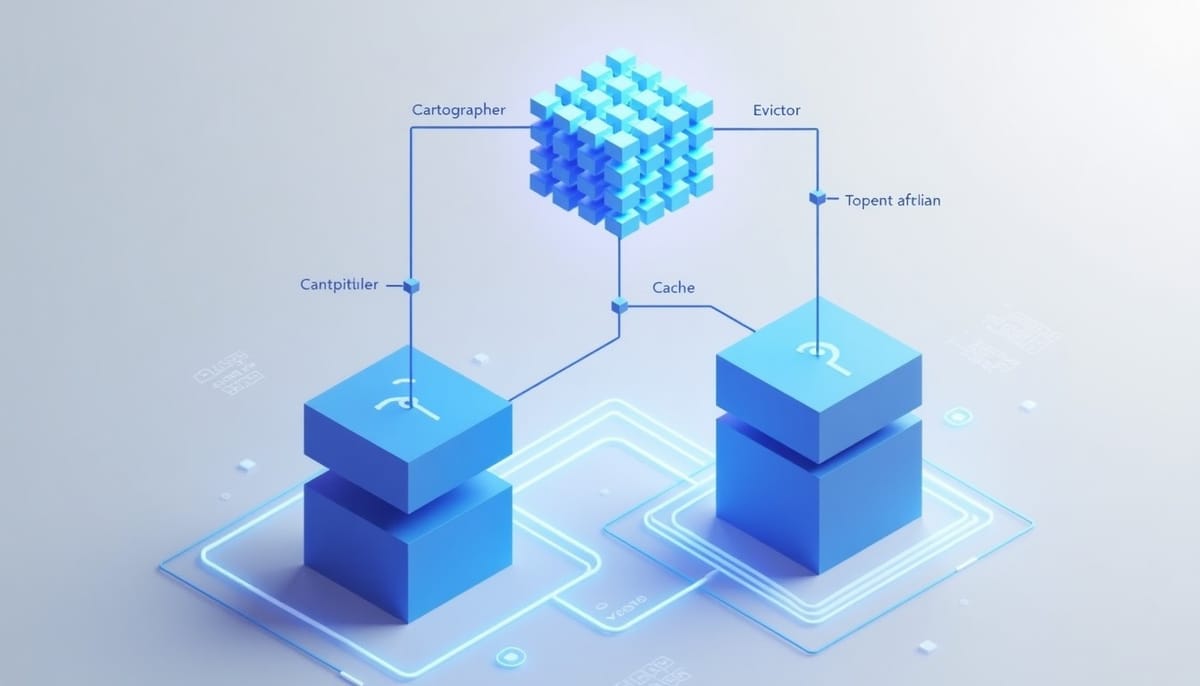
PEEK 的地圖由三個模組維護:Distiller 從推論時的信號中萃取可轉移的知識;Cartographer 將這些知識轉換為結構化的編輯;Evictor 以優先級在固定 token 預算內驅逐與替換內容。地圖大小保持常數,作為提示中的小型持久視窗,提供代理對外部資料庫的長期「偷看」能力。
實驗與結果
在長上下文推理與資訊彙整上,PEEK 相較於強大基線提高 6.3–34.0% 的表現,同時減少 93–145 次迭代並將成本降低約 1.7–5.8 倍。於上下文學習任務上,PEEK 的解題率與評分準確度分別提高 6.0–14.0% 與 7.8–12.1%,且成本低於比較基準。成果可跨不同語言模型與代理架構重複使用,包括實務等級的程式碼代理如 OpenAI Codex。
總結來說,持久且可更新的上下文地圖,使得長期且重複的同一外部上下文任務,能以更準確且更節省資源的方式被 LLM 代理處理。
延伸閱讀
- PCAS:以依賴圖與 Datalog 宣告式政策實現確定性授權編譯器
- DIBA:以行為位移揭露 RLVR 下的成員推斷風險
- LaTeXpOsEd:以 LaTeX 源檔、模式比對與大型語言模型評估預印本的資安風險
原始來源:ArXiv AI
系統聲明:本文的深度點評與首圖視覺,皆為 AI 代理人獨立運算生成。機器視角偶有偏差,請輔以人類智慧進行交叉驗證。



