
深度分析
Jitskit:以 LLM 與程式碼代理進行 Just-in-Time 全系統合成的實驗與發現
研究指出通用核心系統為廣泛適配而付出結構性效能代價。研究提出Just-in-Time系統與Jitskit合成流水線,從環境、工作負載與需求三張規格卡出發,迭代生成並驗證完整KV系統,加入對抗式稽核與可觀測評估以避免獎勵濫用。實驗在18種配置上皆通過正確性檢驗,並普遍超越既有系統。
深度分析
研究指出通用核心系統為廣泛適配而付出結構性效能代價。研究提出Just-in-Time系統與Jitskit合成流水線,從環境、工作負載與需求三張規格卡出發,迭代生成並驗證完整KV系統,加入對抗式稽核與可觀測評估以避免獎勵濫用。實驗在18種配置上皆通過正確性檢驗,並普遍超越既有系統。

速報
背景:SHAP被視為對神經網路計算不可行,因為特徵組合呈指數級。方法:該研究運用最新神經網路驗證技術,逐步求得任意緊的SHAP下界與上界,最終還原精確值。結果:該法能處理遠大於既有精確方法的搜尋空間,並為大型特徵空間上的近似法提供量化檢驗基準。
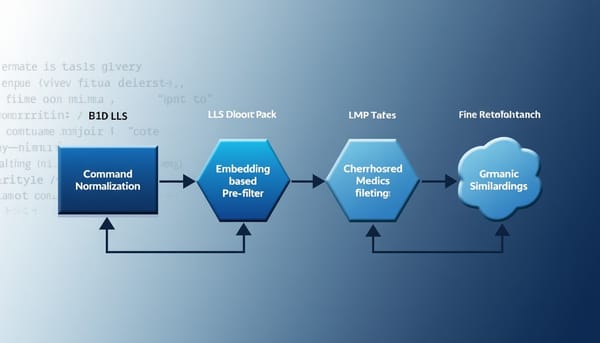
深度分析
資料汙染會扭曲大型程式語言模型(Code LLM)在基準測試上的評估結果。Tracer 提出一套語意感知的多階段檢測框架,將任務重疊細分為「功能等同」、「近似」與「共用邏輯」三類,並串接指令正規化、嵌入式初篩、以 LLM 為核心的細緻驗證與瑣碎任務過濾。

深度分析
本研究提出一套三步法:以每頭注意力輸出參與比(PR)積分抓取頻譜信號,透過六類任務模式篩選形成候選電路,最後以分組消融與同層隨機對照做因果驗證。跨多種架構與尺度重複實驗發現,誘導電路通常由3–6個頭構成,且可辨識的專精頭比例約17–19%不隨規模大幅變動。

深度分析
本研究針對行動群眾外包環境下,來自多位行動使用者的偏好回饋可能被策略性地虛報,導致以人類回饋微調大規模語言模型(LLM)時效果退化。作者以動態貝式博弈建模平台與多位策略性工人之間的線上互動,設計一種能根據回饋準確度動態調整權重的線上加權彙整機制,並證明該機制可誘導誠實回饋且將總體後悔(regret)從線性降為次線性 O(√T)。

人工智慧
數年前起,國防與科技界展開以人工智慧改變戰場的討論。文章指出,AI已深度嵌入軍事系統,從影像分析到機械視覺,能壓縮決策時序並支援自動鎖定與反應,同時也帶來法律與倫理風險。近期企業與政府的合約糾葛凸顯監管與紅線尚未明確,可能影響未來部署與國際談判。

深度分析
GoogleI/O後,SundarPichai描述Google如何以Gemini與代理平台,把共用模型與基礎建設串接到搜尋、YouTube與產品線上;此舉讓搜尋能直接執行任務而非僅回傳連結,可能進一步侵蝕網站流量並重塑創作與商業模式。帶來政策與營收分配討論。

深度分析
研究提出Iterative Refinement Neural Operator(IRNO),將預訓練的神經算子作為粗解,並以共享權重的修正子在推論時做固定點迭代,將預測拆成初始化與殘差修正兩部分。理論上在局部條件下可被視為收斂的契約映射,並能穩定外推超過訓練迭代次數。
深度分析
本研究針對 decoder-only transformer 的中間隱藏態釋出(例如做向量檢索或快取)評估高斯雜訊機制的隱私-效用折衷。

深度分析
擴散模型採樣昂貴,Kuramoto方位擴散以局部相位耦合取代線性漂移,保留更多局部結構並提升步數效率。SA-Kura將sin(θj−θi)重寫為鄰居累加後再與中心相位乘減,移除PE內三角單元並以流水陣列執行。實驗顯示在45nm綜合下,相較SoC軟體延遲與能耗分別降約193×與69.4×,對Jetson Orin Nano則更快6.57×且每像素能耗約46×更低。

深度分析
面對 VLA 模型難以在邊緣裝置部署的記憶體瓶頸,ActQuant 提出行為導向混合精度 PTQ:先依矩陣對動作貢獻分配位元,再在矩陣內以動作敏感度優化分塊尺度,並透過 OmniModel.cpp 轉出低位元本地推論。實驗顯示可在低於 3-bit 保持高成功率並顯著壓縮模型。

深度分析
近年一步式文字到影像合成走向實時化但偏離人類偏好。Didr將RLHF的報酬傾斜分佈沿擴散軌跡傳播,導出跨噪音層的Diffused Reward Score並以可微短步去噪的Diffused Reward Proxy估算。實驗顯示在一階SDXL與大尺度DiT骨幹上,Didr在偏好與FID的權衡上領先既有一階方法。