深度分析
從公開歌單推斷使用者屬性:musicPIIrate 框架與 JamShield 防護機制解析
研究指出,公開音樂歌單可被OffensiveAI工具musicPIIrate解析出使用者年齡、性別、嗜好等隱私資訊,使用圖神經與DeepSets模型提升屬性推測準確度,並提出注入虛擬歌單的JamShield防禦,可降低推論準確度約10%,顯示此攻擊對使用者隱私構成新興威脅。
深度分析
研究指出,公開音樂歌單可被OffensiveAI工具musicPIIrate解析出使用者年齡、性別、嗜好等隱私資訊,使用圖神經與DeepSets模型提升屬性推測準確度,並提出注入虛擬歌單的JamShield防禦,可降低推論準確度約10%,顯示此攻擊對使用者隱私構成新興威脅。

深度分析
研究延伸潛在遞迴模型,提出快速‑慢速循環模型(FSRM)以觀測慢速、推理快速雙通道同時更新,實驗顯示在Dyck與迷宮等長程任務上保持約90%正確率,並優於LSTM、Transformer等基線。模型在不同長度序列上保持表現,減少對基線策略的位移,提升持續學習能力。
深度分析
隨著多模態大型語言模型需同時處理音訊與影像,令牌數量激增成為推論瓶頸。研究提出動態音訊驅動語意分塊(DASH)以音訊嵌入作為語意錨點,偵測相似度斷層並投射至影像,結合邊界、獨特性與注意力三信號評估重要性,實現結構感知壓縮。實驗顯示在25%保留率下仍保持或超越既有方法,提升預填速度與端到端延遲。

深度分析
研究針對文本嵌入模型在語意推理任務上的深度不足,提出測試時多次前向的 Refine Thought 方法,透過時間展開提升推理步數,實驗在 BRIGHT 與 PJBenchmark 上取得顯著改善,同時在 C‑MTEB 上維持穩定表現。此方式不同於一次前向或CoT,透過測試時展開提升推理深度,預期有助檢索與代理系統。
深度分析
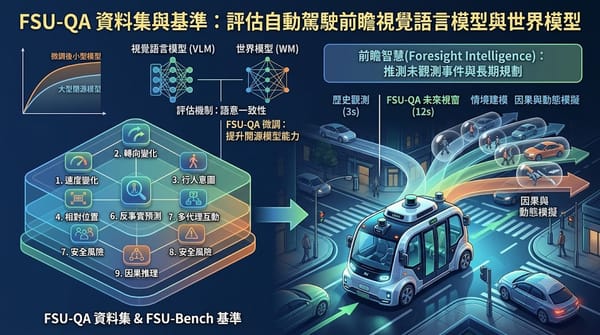
研究背景:視覺語言模型多聚焦於即時感知,忽略未來推測。核心做法:提出FSU‑QA資料集與FSU‑Bench基準,設計九項自駕前瞻任務,並以VLM評估World Model生成之未來影像之語意一致性。主要結果:即使是小型模型經FSU‑QA微調,也能超越多數大型閉源模型,顯示該基準有效提升前瞻推理能力。

大佬動態
Meta 於 2026 年 7 月公布 Muse Spark 1.1,為首款提供 API 的 Spark 系列模型。官方稱其在代理式工具呼叫與電腦操作上有顯著提升,並在防止 jailbreak、降低幻覺與提升提示注入防禦方面表現更佳。

深度分析
研究針對擴散模型的負向分類自由指導(negative CFG)提出對比式改進(CCFG),利用對比損失在正負概念間拉扯,引導去除不想要的特徵,同時保持樣本品質。實驗顯示在多種條件下均能有效抑制不良概念。此方法亦兼具計算效率,避免大型獎勵模型的訓練成本,為線上個人化生成提供實務可行性。

深度分析
研究指出,大型語言模型在壓縮財報與電話會議文字時,常會遺失關鍵情境,使投資判斷翻轉。作者提出多候選壓縮與原文比對的代理式上下文壓縮流程,顯著降低決策翻轉率。實驗以 S&P 100 企業 2025 年第一至第三季的 10‑Q MD&A 以及盈餘說明會稿為樣本,顯示單一壓縮模型的翻轉率可達 20% 以上。

深度分析
隨著程式碼代理人逐漸使用子代理處理繁雜的終端輸出,研究者提出以4B參數的Terminus-4B取代大型模型。透過專屬的執行子代理與雙階段微調,模型在SWE‑Bench系列基準上減少約30%代幣使用,同時保持或超越前沿模型效能。實驗顯示,即使僅使用4B參數模型,亦能在多語言專案如C#測試中保持高解決率。此技術有望降低部署成本並提升代理人效率。

速報
Meta在重新進軍AI領域後,於本週推出升級版的Muse Spark 1.1模型,並透過全新Meta Model API向美國開發者提供公測。新模型在程式碼生成、錯誤偵測與修復、以及多模態感知方面較第一代有顯著提升,並支援跨應用的代理工作流程。Meta同時提供每帳號20美元的免費點數,讓開發者能在Meta AI App與網站上即時體驗。

深度分析
研究發現大型語言模型在處理否定指令時常出錯,開源模型在簡單否定下錯誤贊同禁令高達77%至100%,商業模型亦出現19%至128%的極端波動,醫療情境較金融情境更易受影響。作者提出否定敏感度指標(NSI)作為安全治理度量,並建議以領域門檻分層認證,降低高風險應用的安全風險。

深度分析
傳統分析工作負載必須透過JDBC/ODBC走線,造成高延遲。研究提出Jailbreak,利用大型語言模型自動合成可直接讀取PostgreSQL與MySQL儲存檔的欄位緩衝讀取器,輸出ApacheArrow。實驗顯示在多種分析引擎上可提升27倍效能,證明LLM輔助的存儲層解耦能突破資料鎖定。