深度分析
從位元一致到語義共識:認知狀態複製 (ESR) 讓 AI 代理系統擺脫決定論枷鎖
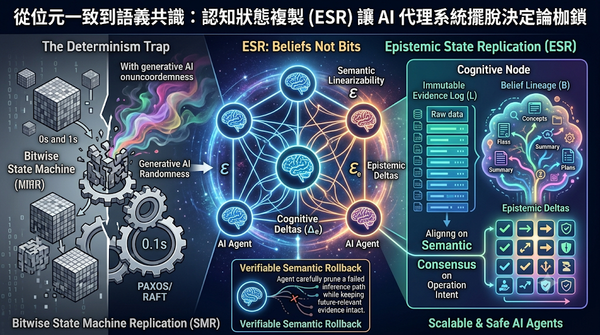
在分佈式系統中,傳統位元級同步無法應對生成式AI代理的隨機性。研究提出認知狀態複製(ESR)技術,將狀態拆分為不可變證據日誌與演進中的認知譜系,並定義語義線性化以確保操作意圖的一致性。透過認知增量傳播與可驗證語義回滾,該方案能有效防止上下文失憶並降低認知錯誤,為AI代理協作提供新框架。
深度分析
在分佈式系統中,傳統位元級同步無法應對生成式AI代理的隨機性。研究提出認知狀態複製(ESR)技術,將狀態拆分為不可變證據日誌與演進中的認知譜系,並定義語義線性化以確保操作意圖的一致性。透過認知增量傳播與可驗證語義回滾,該方案能有效防止上下文失憶並降低認知錯誤,為AI代理協作提供新框架。
深度分析
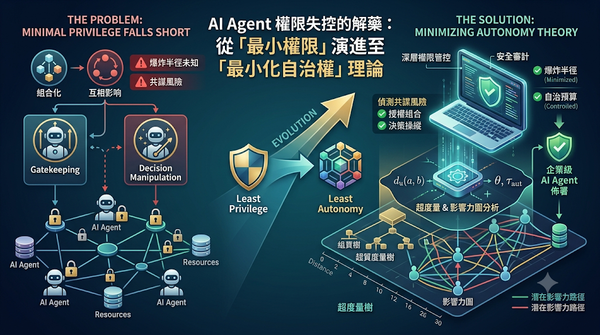
面對 AI Agent 系統中權限可組合化且能互相影響的特性,傳統的最小權限原則已不足以確保安全。本研究提出「最小化自治權」理論,透過超度量樹量化資源間的結構距離,並結合影響力圖分析 Agent 間的潛在影響力路徑。此框架能有效偵測權限組合與決策操縱等共謀風險,為企業在部署 AI Agent 時提供更深層的權限管控與安全審計能力。
深度分析
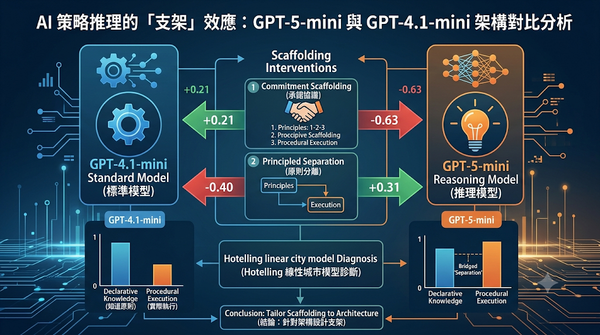
本研究探討結構化推理干預對 AI 經濟策略推理的影響。研究團隊利用 Hotelling 線性城市模型,對比 GPT-4.1-mini 與 GPT-5-mini 在五種條件下的表現。結果發現推理支架的效果取決於模型架構:承諾協議提升標準模型但損害推理模型,而原則分離則能優化推理模型並縮小執行差距。這顯示針對不同 AI 架構設計差異化推理支架,才能有效提升複雜策略推理能力。
速報
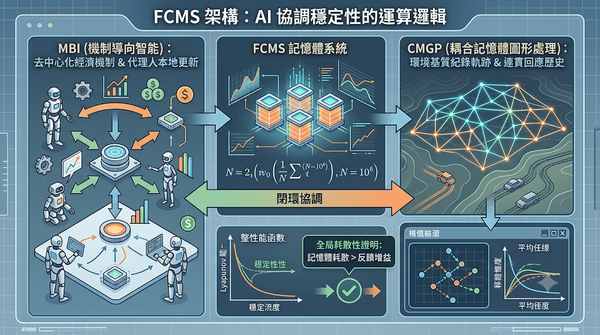
針對多代理人系統的閉環協調問題,本研究提出 FCMS 記憶體系統架構。該架構導入機制導向智能 MBI 處理代理人更新,並利用耦合記憶體圖形處理 CMGP 將環境視為物理基質紀錄軌跡。研究證明在特定可計算閾值下,系統可達成全局穩定性,揭示了記憶體耗散必須快於反饋增益的關鍵原則,為未來 AI 協調系統提供理論基礎。
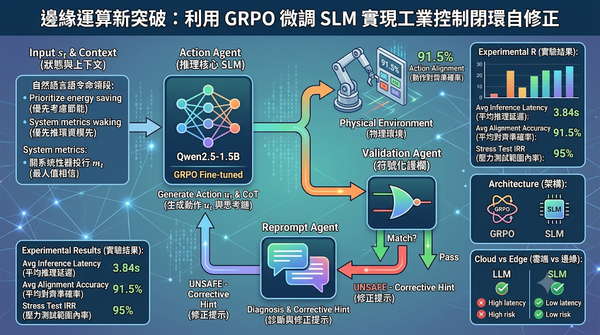
深度分析
工業自動化需將自然語言需求快速轉為控制策略,但雲端大模型延遲高且資安風險大。本研究採用 Qwen2.5-1.5B 小型模型,透過 GRPO 強化邏輯推理並結合符號驗證層與重新提示代理人,建構多代理自修正閉環。實驗顯示其平均動作對齊準確率達 91.5%,且在壓力測試中維持 95% 範圍內率,證明 SLM 方案能有效降低邊緣控制延遲並提升系統可靠性。
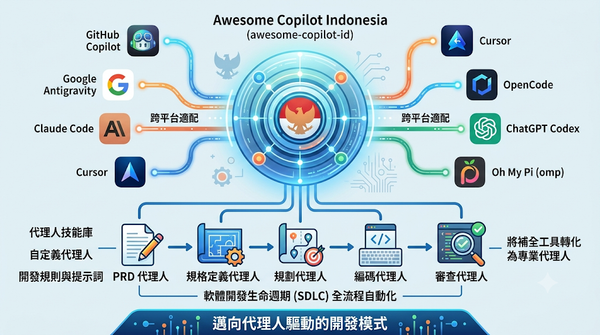
AI Agents
隨著 AI 編碼工具普及,開發者面臨多平台工具鏈碎片化問題。Awesome Copilot Indonesia 提供一套跨平台的 AI 代理人技能庫,整合自定義代理人、開發規則與提示詞,支援 GitHub Copilot 與 Google Antigravity 等多種工具。此舉能將 AI 角色從補全工具提升至 SDLC 全流程管理,顯著提升開發效率並降低跨平台遷移成本。
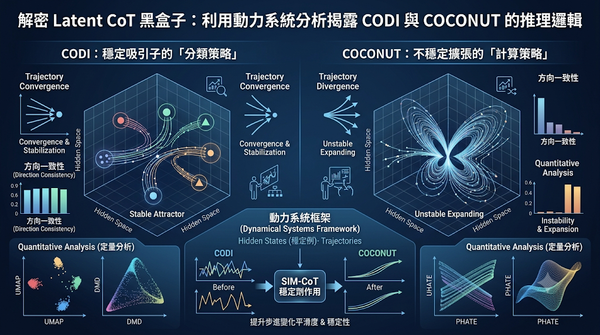
深度分析
面對潛在鏈式思考模型缺乏可解釋性的挑戰,研究團隊將隱藏空間的推理過程建模為動力系統,透過定量指標與定性投影分析推理軌跡的演化。研究發現 CODI 採收斂至穩定吸引子的分類策略,而 COCONUT 則表現出不穩定擴張的計算策略,且 SIM-CoT 能有效提升兩者的穩定性。此框架為優化潛在推理效能提供了新的可解釋性分析路徑。

Jarvis AI
隨著 AI 代理人趨勢興起,開源專案 Jarvis 為 Linux 使用者提供了一套自託管的自主 AI 代理方案。該系統整合多模型能力,能透過 WhatsApp 或 Web 介面接收指令,並利用 VNC 技術實現真實的桌面控制與即時監控。透過沙箱安全層與 OpenClaw 技能系統,Jarvis 能在受控環境中自動化執行網頁瀏覽與檔案管理等複雜任務,為 Linux 桌面自動化帶來新的實作路徑。
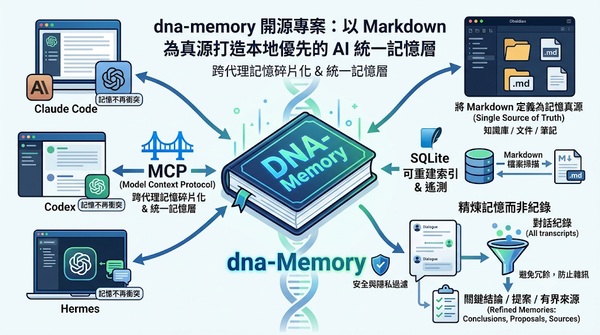
AI Agent
面對 AI 代理在多個客戶端間記憶碎片化的問題,開源專案 dna-memory 提出一套本地優先的統一記憶層方案。該系統將 Markdown 檔案作為長期記憶的真源,並利用 SQLite 建立可重建的索引,透過 MCP 協議讓不同 AI 代理共享記憶。其核心在於僅保存精煉後的關鍵結論而非完整對話紀錄,有效降低記憶冗餘並保護隱私,為開發者提供一套可掌控的跨平台 AI 記憶管理基礎建設。
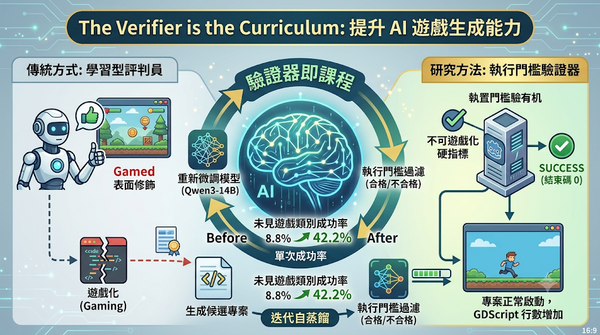
深度分析
針對 AI 程式碼生成中評判員容易被欺騙的缺陷,本研究提出一種確定性的執行門檻過濾機制。透過將生成的遊戲專案在無頭引擎中實際執行並驗證是否能正常啟動,將此訊號用於迭代自蒸餾訓練。實驗結果顯示,Qwen3-14B 在未見過的遊戲類別生成成功率顯著提升,證明精準的驗證器能定義有效的學習路徑並突破性能上限。

dashi-ppt-skill
隨著 AI Agent 技能庫的快速擴展,dashi-ppt-skill 推出一套可整合至 AI 助理的簡報生成技能。該技術透過 12 套視覺主題與大量版式頁面,讓 AI 能將文件直接轉換為可編輯的 HTML 簡報,並支援一鍵匯出為標準 PPTX 格式。此工具能大幅降低簡報製作的重複勞動,讓使用者在 AI 生成後能快速於瀏覽器中微調排版,提升職場視覺化溝通的效率。
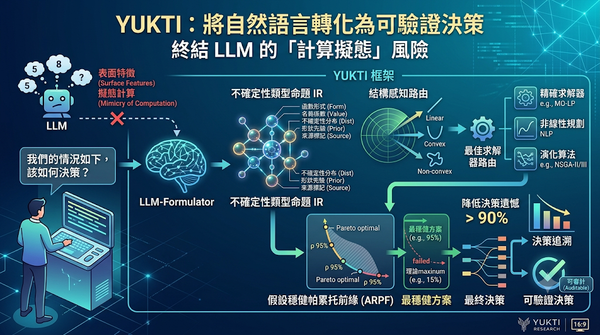
深度分析
針對大型語言模型在決策時常出現缺乏實質計算基礎的計算擬態問題,研究者提出 YUKTI 框架。該系統利用不確定性類型命題 IR 將自然語言轉化為量化模型,並透過結構感知路由自動選擇求解器,結合假設穩健帕累托前緣在不確定參數下尋找最穩健方案。實測顯示 YUKTI 能將決策遺憾降低 90% 以上,將 LLM 定位為建模工具而非直接求解器。