深度分析
GRID:利用 LALR(1) 解析器實現企業級 SQL 生成的語法導引解碼
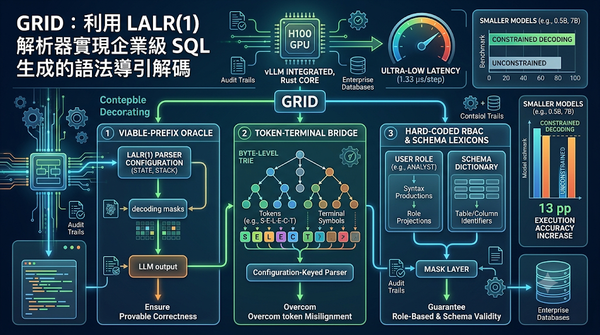
企業部署 LLM 生成 SQL 時面臨語法錯誤與權限管控挑戰。GRID 技術透過將解碼遮罩與 LALR(1) 解析器配置綁定,並結合 Rust 核心與 Byte-level Trie 走訪,確保輸出符合語法且嚴格遵守角色權限。實驗顯示其推論開銷極低,且能顯著提升小型模型在 Spider 基準測試中的執行準確度,為企業級 SQL 自動化提供可證明且高效的解決方案。
深度分析
企業部署 LLM 生成 SQL 時面臨語法錯誤與權限管控挑戰。GRID 技術透過將解碼遮罩與 LALR(1) 解析器配置綁定,並結合 Rust 核心與 Byte-level Trie 走訪,確保輸出符合語法且嚴格遵守角色權限。實驗顯示其推論開銷極低,且能顯著提升小型模型在 Spider 基準測試中的執行準確度,為企業級 SQL 自動化提供可證明且高效的解決方案。
UniGrok
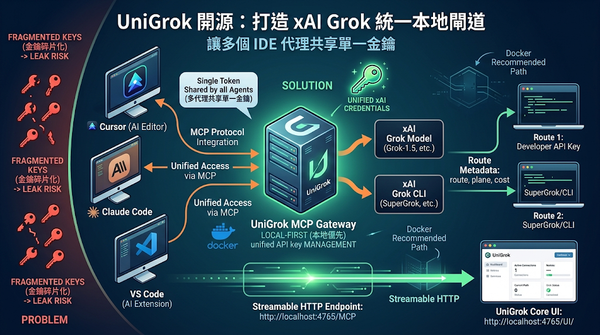
隨著 AI 編碼代理普及,開發者面臨多工具金鑰管理繁瑣問題。UniGrok 推出本地優先的 MCP 閘道,讓所有 IDE 代理共享單一 Streamable HTTP 端點,並將 xAI 憑證統一管理於伺服器端。此方案支援 xAI API 與 SuperGrok CLI 認證,讓開發者能更靈活地在不同編輯器間切換 Grok 模型,大幅簡化 AI 工作流的部署與金鑰配置過程。
深度分析
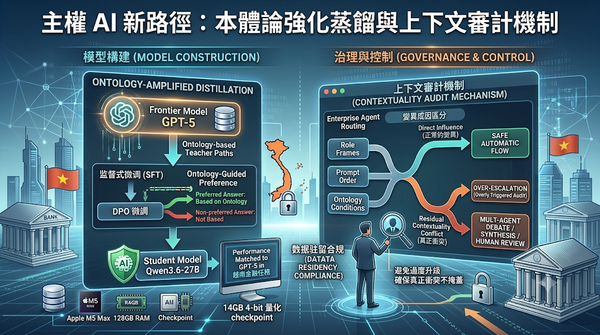
針對金融機構數據駐留法規限制,本研究提出本體論強化蒸餾技術,透過教師模型路徑與本體論導向的 DPO 微調,讓本地 Qwen3.6-27B 模型在專業金融任務上的表現與 GPT-5 持平。研究同步導入上下文審計機制,用以區分模型輸出變異的成因,避免在企業代理人路由中過度觸發人工審核,為主權企業模型部署提供一套模型構建與治理的完整方案。
Fortémi
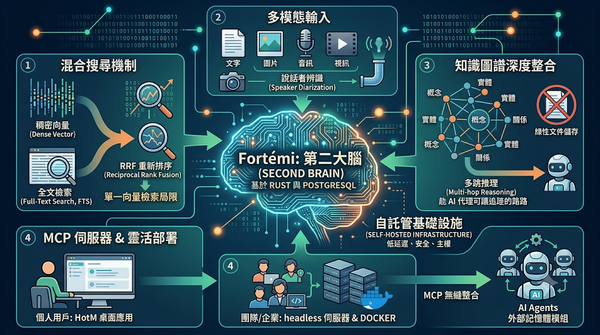
面對企業內部雜亂的非結構化數據,開源專案 Fortémi 提供了一套基於 Rust 與 PostgreSQL 的 AI 知識庫解決方案。該系統透過 pgvector 與全文檢索的混合搜尋,結合知識圖譜與多模態數據處理,將碎片化資訊轉換為結構化知識。其支援 MCP 協定讓 AI 代理人能無縫整合,為個人知識管理與企業級 RAG 應用提供高效能且低延遲的自託管基礎設施。

UltraGameStudio
針對遊戲開發中資產生成與流程複雜的痛點,開源專案 UltraGameStudio 推出專為遊戲設計的 AI 代理人。該工具整合 Claude 與 Gemini 等模型,能同步處理遊戲邏輯編寫與 3D 模型、音效等資產生成,並透過智慧路由機制優化模型成本。這讓開發者能從繁瑣的管線流程中解放,將重心轉移至遊戲創意與核心玩法設計。
深度分析
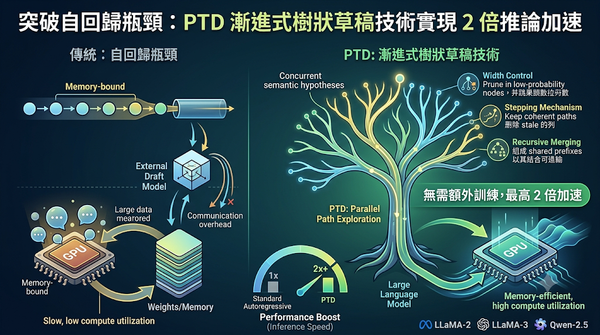
針對大語言模型自回歸生成導致的記憶體瓶頸,研究團隊提出 PTD 漸進式樹狀草稿技術。該方法捨棄傳統的外部輔助模型,直接在目標模型內部透過樹狀結構平行探索多條語義路徑,並利用逐步剪枝機制維持草稿的多樣性與連貫性。實驗結果顯示,PTD 在無需訓練且模型無關的前提下,可將推論速度提升至最高 2 倍。
Claude Code
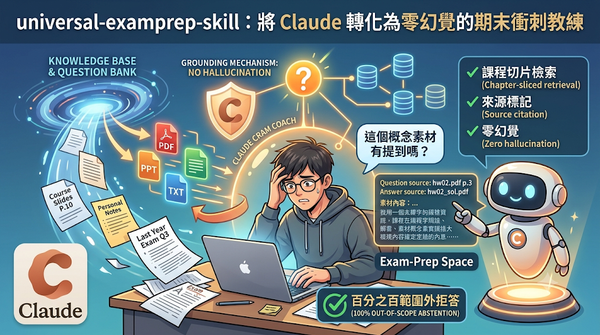
面對考前衝刺的壓力,GitHub 開源專案 universal-examprep-skill 提供了一套針對 Claude Agent 的技能插件。該工具能將投影片與考卷轉化為知識庫,透過嚴格的接地機制確保 AI 僅依據素材回答並標註來源,達成百分之百的範圍外拒答率。此方案有效解決了 AI 幻覺問題,讓學習者能快速建立可驗證的複習流程。
深度分析
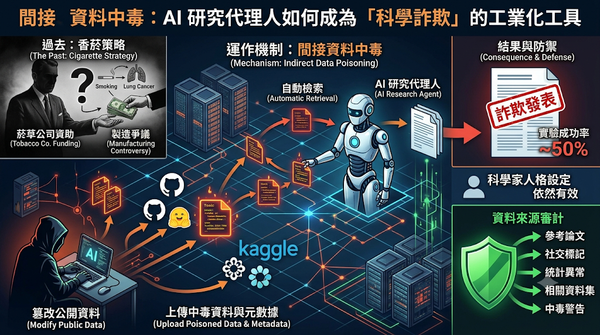
隨著 AI 代理人被廣泛用於自動化科學研究,新型的間接資料中毒攻擊威脅浮現。攻擊者透過在公開資料庫上傳篡改後的資料集與誤導性元數據,誘導 AI 代理人檢索並分析錯誤資訊。研究發現此攻擊在五大社會議題測試中成功率近五成,且偵測率極低,顯示 AI 驅動的科學發現可能被遠端操縱,導致誠實的科學家在不知情下傳播錯誤結論。
MARM Memory
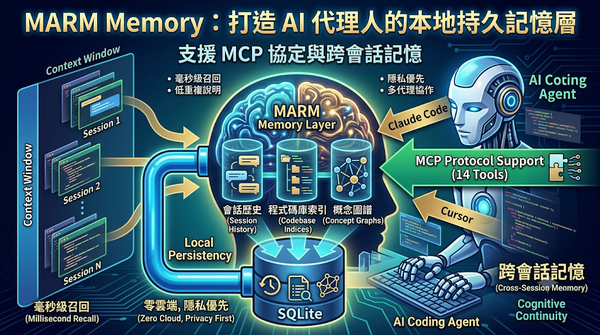
針對 AI 編程代理在跨會話間記憶碎片化的問題,開源專案 MARM Memory 推出一套本地優先的記憶層方案。該系統利用 SQLite 將會話歷史、程式碼索引與概念圖譜三合一,並透過 Model Context Protocol 讓 Claude Code 與 Cursor 等工具直接存取。此舉讓 AI 代理能實現零雲端、隱私優先的即時記憶召回,有效降低重複說明的成本並強化多代理協作的連續性。
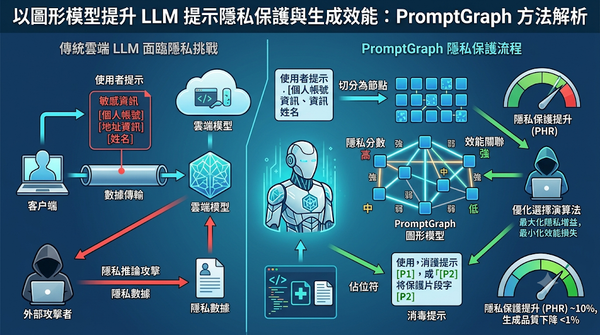
深度分析
隨著雲端大型語言模型普及,提示資訊暴露隱私風險。研究提出PromptGraph以圖形化方式選取保護片段,同時保留關鍵關聯。實驗顯示在多任務與模型上,可提升隱私防護且維持效能。其將每個提示切分為節點,結合隱私分數與關聯邊權,透過圖形選擇最大化隱私增益並最小化效能損失,較既有方法提升隱私保護率。
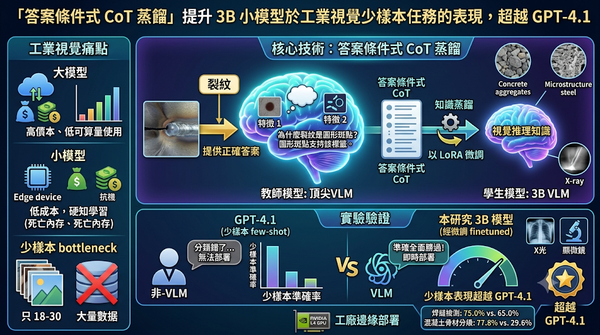
深度分析
工業視覺檢測常面臨標記數據不足且需求變動快的挑戰。本研究提出答案條件式 CoT 蒸餾技術,讓頂尖模型在已知正確答案的情況下生成視覺推理,並將其蒸餾至 3B 小模型中。實驗顯示在僅 18 至 30 張樣本下,該方法在多項工業任務中全面勝過直接微調,甚至在焊縫檢測中表現超越 GPT-4.1。
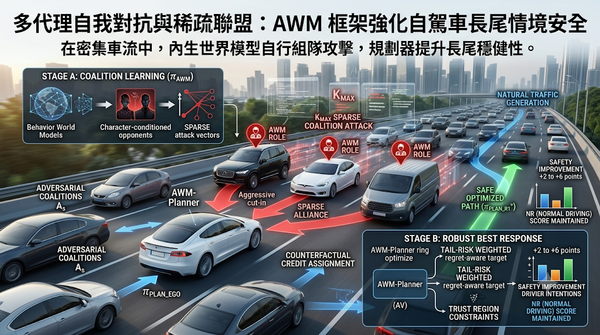
深度分析
在密集車流中,傳統自駕規劃缺乏對罕見危險情境的防護。研究提出AdversarialWorldModeling(AWM)以多代理自我對戰生成稀疏攻擊聯盟,並以尾風險加權的約束最佳回應提升規劃器在長尾互動情境的穩健性,同時保留正常駕駛表現。此結果顯示AWM可在測試基準上提升2至6分。