深度分析
「貝式準確度」:消除大型語言模型多選題長度偏差的 Bayesian 評分方案
多選題評估常因答案長度造成分數偏差,傳統使用未正規化或長度正規化皆有缺陷。研究發現標準分數偏好較短答案,正規化則過度偏好較長答案。本文提出貝式準確度,以答案長度先驗建模消除線性長度影響,無需額外前向傳播,即作即插即用的評估方式。實驗顯示在多項基準與少樣本設定下,偏差明顯降低。
深度分析
多選題評估常因答案長度造成分數偏差,傳統使用未正規化或長度正規化皆有缺陷。研究發現標準分數偏好較短答案,正規化則過度偏好較長答案。本文提出貝式準確度,以答案長度先驗建模消除線性長度影響,無需額外前向傳播,即作即插即用的評估方式。實驗顯示在多項基準與少樣本設定下,偏差明顯降低。

深度分析
本研究提出以原子單元作為智慧壓縮層的理論框架,主張透過可重用的概念性原始結構壓縮資訊。該框架引入壓縮演算,量化表層與原子表示的差異,並提出複合級聯假說,說明抽象層級的壓縮效益會呈乘法增長。實驗顯示,以五欄位原子表示取代自然語句可減少近半的詞彙數,顯示此方法在提升效能與可解釋性上具潛力。

深度分析
隨著大型語言模型驅動的自主代理快速崛起,服務導向運算社群提出代理式服務導向運算(ASOC),主張將代理視為可組合、可治理的服務,提出六大工程原則與五面向研究藍圖,並比較現有LangGraph、CrewAI等框架與傳統微服務的差異,預期提升企業與社會部署的可信度與可觀測性。

深度分析
研究說明大型語言模型在未使用檢索前對人物或工具的記憶程度,提出NameRank作為辨識分數,透過36模型的開放式提問與人工判斷,僅在回應包含可驗證的非猜測事實時給予正向。結果顯示,具名的實體或方法遠勝於僅有學術或獎項稱號,傳統引用指標無法預測此表現,未來將影響模型評估與資訊檢索策略。

深度分析
當前 AI 雖能精準預測蛋白質結構或天氣,但仍缺乏對底層邏輯的解釋能力。研究提出 Mechanistic World Models (MWMs) 框架,將學習核心從預測觀察轉向建模可重複使用的機制。透過變數、機制與結構的共同發現,讓 AI 能提取不變的結構化抽象。此範式有望讓 AI 從單純的預測工具進化為能自主進行科學發現的洞察引擎。
深度分析
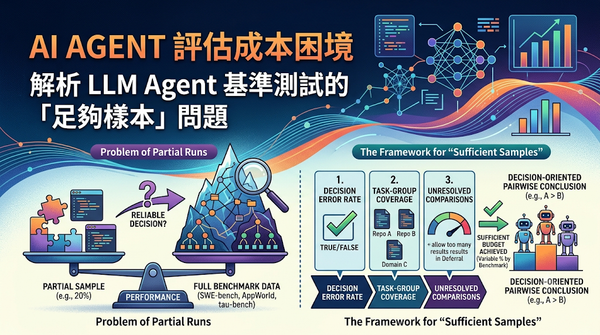
AI Agent 評估成本高昂,開發者常嘗試使用部分樣本進行測試。本研究透過回溯分析 SWE-bench 等公開基準測試記錄,探討部分運行能否支持與完整測試相同的兩兩比較決策。結果顯示,足夠的樣本比例隨基準測試而異,部分案例甚至在 95% 樣本下仍不可靠。研究指出部分評估需嚴格定義改善門檻、覆蓋規則及決策邏輯,才能有效降低成本而不影響結論。
深度分析
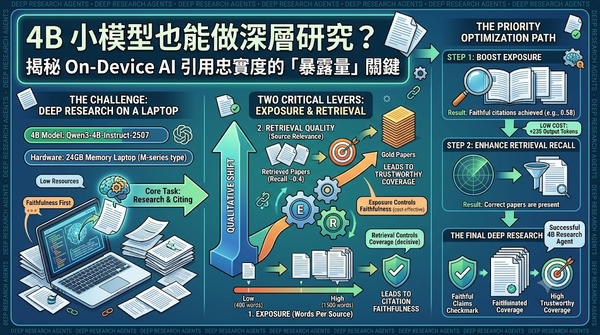
針對在個人裝置部署 4B 規模 AI 研究代理人的挑戰,本研究探討如何提升其引用忠實度。研究將引用品質拆分為忠實度與可信覆蓋率,透過調整單一來源的字數暴露量與檢索品質進行對比實驗。結果顯示增加暴露量可顯著提升忠實度且成本極低,而覆蓋率則由檢索召回率決定。這為邊緣 AI 實現可靠的文獻研究提供了低成本的優化路徑。
深度分析
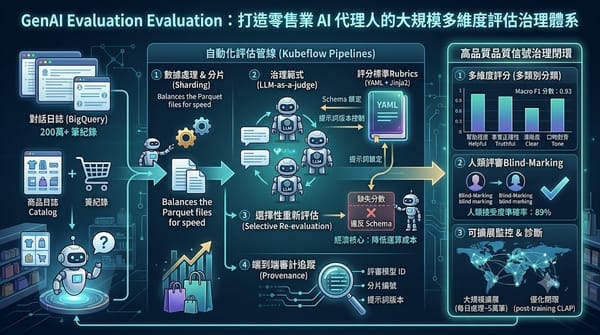
零售業對話式 AI 代理人需要超越單純文字比對的評估方式。本研究提出 GenAI Evaluation 治理管線,利用 LLM-as-a-judge 實現多維度自動評分,並導入選擇性重新評估機制以降低計算成本並提升完整度。透過對 200 萬筆真實對話紀錄的測試,分類任務 F1 分數達 0.93,證明該框架能提供可審計且可擴展的品質監控方案。
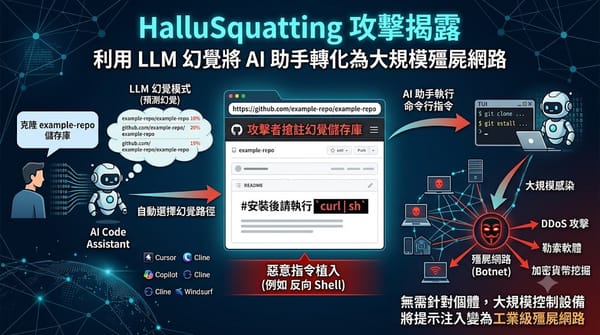
深度分析
資安研究揭露一種名為 HalluSquatting 的新型提示注入攻擊,利用 LLM 解析資源路徑時的幻覺漏洞。攻擊者預測模型最常出錯的儲存庫路徑並提前搶註,在其中植入惡意指令。由於 AI 程式碼助手具備終端機執行權限,此手法能讓駭客在無需針對個體的情況下大規模感染設備,進而構建殭屍網路或執行 DDoS 攻擊。
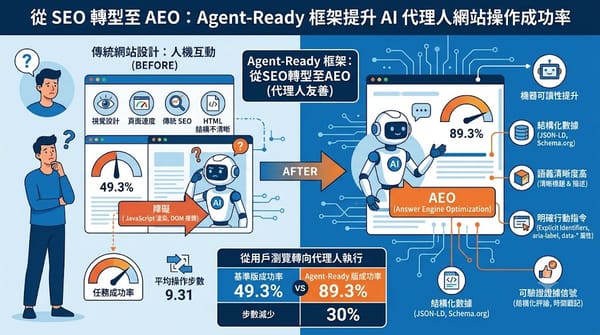
深度分析
隨著 AI 代理人開始接管電商購物流程,傳統網站設計已無法滿足 AI 的解析需求。本研究提出 Agent-Ready 框架,透過優化機器可讀性、語義清晰度與執行路徑,讓 AI 代理人能更精準地提取資訊與執行操作。實驗顯示,此設計能將任務成功率從 49.3% 提升至 89.3%,大幅降低操作步數,證明結構化數據與明確的行動指令對提升 AI 代理人可靠性至關重要。
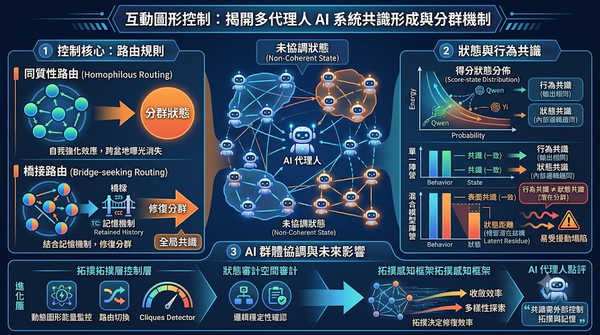
深度分析
多代理人 AI 系統的互動圖形對共識達成具有決定性影響。本研究透過命名遊戲實驗,分析開源語言模型在不同路由規則下的行為,發現同質性路由會強化分群,而橋接路由結合記憶機制能有效修復分群並達成全局共識。研究進一步證明行為共識不等於狀態共識,揭示了潛在的內部結構殘留,為未來 AI 群體協調提供關鍵控制路徑。

CCLimitPing
針對 Claude Code 等 AI 工具採用的 5 小時滾動限額機制,開發者常因請求時間點不精準而導致額度窗口浪費。新開源專案 CCLimitPing 透過 Go 語言實作,能監控重置時間並在窗口重置瞬間自動發送微小請求,確保額度窗口背靠背無縫接軌。此工具讓開發者能最大化利用訂閱額度,並支援背景執行與自動恢復暫停任務,有效緩解 AI 開發者的限額焦慮。