深度分析
「Sibling‑Guided Credit Distillation」提升長程工具使用的信用分配與政策梯度穩定性
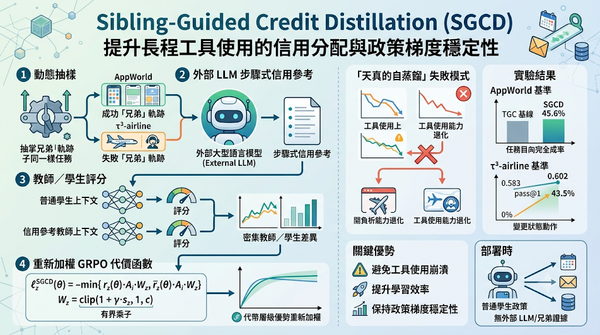
研究聚焦長程工具使用強化學習,提出以兄弟樣本引導的信用蒸餾(SGCD)作為信用分配機制,透過動態抽樣與外部語言模型產生步驟式信用參考,重新加權GRPO代價函數。實驗在AppWorld與τ³‑airline基準上分別提升至45.6%與0.602的pass@1,證明SGCD能避免自蒸餾破壞工具使用。
深度分析
研究聚焦長程工具使用強化學習,提出以兄弟樣本引導的信用蒸餾(SGCD)作為信用分配機制,透過動態抽樣與外部語言模型產生步驟式信用參考,重新加權GRPO代價函數。實驗在AppWorld與τ³‑airline基準上分別提升至45.6%與0.602的pass@1,證明SGCD能避免自蒸餾破壞工具使用。

深度分析
科學研究常需從數據推導出具有解釋力的微分方程,但傳統黑盒模型缺乏透明度。本研究提出 Latent Grammar Flow (LGF) 框架,利用語法量化自動編碼器將方程結構嵌入離散潛在空間,並結合離散流模型與領域知識導向採樣。結果顯示 LGF 在處理顯式與隱式 ODE 時,能比傳統符號回歸方法更高效地發現精確且符合物理特性的數學表達式。
速報
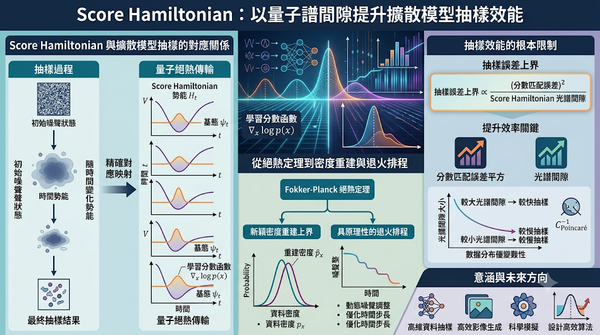
研究顯示分數導向擴散模型抽樣可映射為 Score Hamiltonian 基態的絕熱傳輸。透過時間變化的 Fokker‑Planck 絕熱定理,提出密度重建上界與退火排程。結果指出抽樣上限由分數匹配誤差平方與光譜間隙比值(逆 Poincaré 常數)決定,為抽樣效能提供理論框架。

深度分析
隨著大型語言模型部署需求激增,研究團隊提出 dMX 框架,透過可微分的位元寬度參數化在 MXFP 系列間平滑切換,並以溫度退火將學得的連續偏移離散化。實驗顯示在 Llama、Qwen3 與 SmolLM2 上,同時降低平均位元至 5.2 時仍保持或提升準確度,為低精度浮點部署提供更佳效能。
速報
設計轉程式(design-to-code)技術能將高保真 UI 設計直接產出可執行的前端程式碼,但缺乏一致的資料集與評估標準。研究團隊推出 1D-Bench 基準,以真實電商工作流程為基礎,提供參考渲染圖與可能含錯誤的中介表示,測試模型在不完美中介資料下的韌性。

深度分析
研究以超過15億張影像文字配對與10億段影片標籤,建構統一視覺模型Xray‑Visual。模型採三階段訓練:自監督MAE、半監督標籤分類與CLIP對比學習,並以EViT令token效率提升。實驗顯示在ImageNet、Kinetics及MS‑COCO上均創新紀錄,同時在域轉移與對抗擾動下保持韌性。

深度分析
在視覺語言模型的社會認知測試中,研究團隊以 FlipSet 這套 L2 視覺視角推理基準,對 103 種公開模型進行零樣本評估。結果顯示,超過七成的回答是自我中心的相機視角,整體正確率僅 9%,遠低於 25% 的機會水平,說明模型在將他人視角與空間旋轉結合時存在根本缺失。此問題若不解決,將限制多模態 AI 在真實互動情境中的應用。

深度分析
隨著雙手靈巧操作需求提升,研究推出 DECO 解耦多模態擴散變換器,分別注入視覺、proprioception與觸覺資訊,並搭配輕量觸覺插件與50小時、500萬格的DECO-50資料集,實驗顯示平均成功率達72.25%,觸覺適配器另提升10.25%。

速報
針對多個演算法推理任務同時執行時產生的干擾問題,研究團隊提出 Branching Neural Networks 新架構。該技術透過梯度親和力將任務遞迴地分區為樹狀結構,將複雜度從指數級降低至線性級。實驗證明此方法在 CLRS 基準測試中表現更佳,且運行時間減少 48% 並降低 26% 記憶體使用量,有效提升了多工演算法推理的效率與準確度。

深度分析
隨著多模態大型語言模型在視覺問答與影像描述等任務上表現突出,研究者發現現有解釋方法忽略模態內部相互作用。為此提出多尺度說明聚合(MSEA)與激活排名相關(ARC)兩項技術,分別整合多解析度影像與抑制前文干擾。實驗顯示在 COCO Caption 等基準上解釋精度提升 3.7% 至 14.5%,提升模型透明度與風險可控性。
深度分析
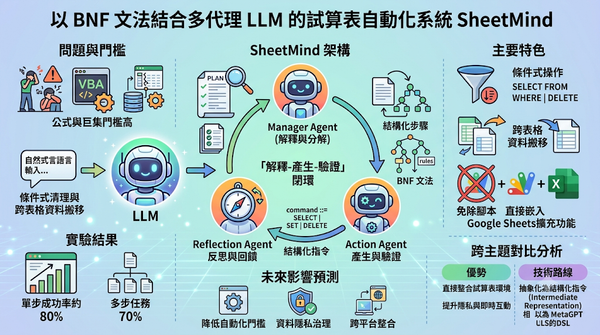
大型語言模型提升試算表可用性,但公式與巨集仍是門檻。SheetMind 以管理、動作、反思三代理人,將指令分解、以 BNF 文法產生結構化指令並即時驗證。同時支援條件式清理與跨表格資料搬移,提升工作流彈性。實驗顯示單步成功率約 80%,多步達 70%,且直接以 Workspace 擴充功能嵌入 Google Sheets,免除腳本部署,提升隱私與即時互動。

速報
本研究針對 Option-Critic 框架在強化學習中面臨的兩大挑戰——選項行為高度相似與可用選項數量縮減——提出解決方案。作者引入資訊理論式內在獎勵以及新穎的終止目標,以促進選項集合的行為多樣性。