深度分析
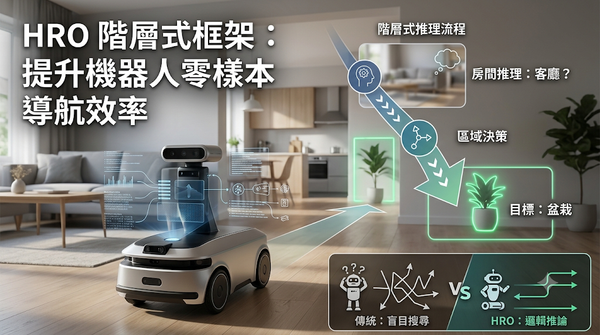
HRO 框架利用 LLM 階層式推理,提升機器人零樣本目標導航效率
在未知環境的零樣本目標導航中,機器人常因缺乏空間認知而盲目探索。研究團隊提出 HRO 階層式框架,模仿人類先判斷房間類型再尋找物體的邏輯,將導航分解為房間推理、區域決策與路徑執行三層結構。該框架將房間類型作為語義橋樑,利用 LLM 常識提升導航精準度。實驗結果顯示 HRO 在 Gibson 與 HM3D 數據集上取得了更佳的成功率與泛化能力。
深度分析
在未知環境的零樣本目標導航中,機器人常因缺乏空間認知而盲目探索。研究團隊提出 HRO 階層式框架,模仿人類先判斷房間類型再尋找物體的邏輯,將導航分解為房間推理、區域決策與路徑執行三層結構。該框架將房間類型作為語義橋樑,利用 LLM 常識提升導航精準度。實驗結果顯示 HRO 在 Gibson 與 HM3D 數據集上取得了更佳的成功率與泛化能力。

深度分析
面對歐洲專利局日益增加的 AI 輔助申請壓力,現有 AI 文本檢測器在專利審查中面臨嚴峻挑戰。研究指出,專利法規對文字簡潔性的強制要求導致人類撰寫的文本與 AI 生成內容在機率分佈上高度重疊,形成所謂的「困惑度陷阱」。實驗顯示主流檢測器的誤判率普遍超過 60%,而改用語言複雜度特徵分析可顯著提升辨識準確率。
深度分析
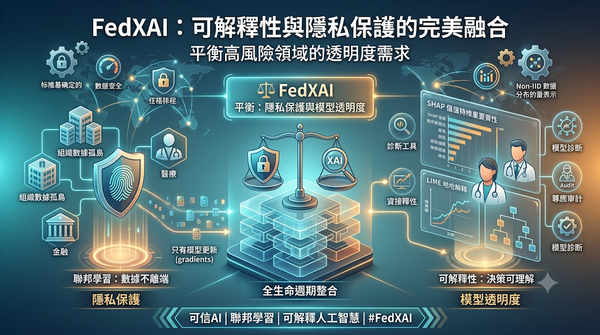
面對分散式數據的隱私限制,聯邦學習雖能保護數據但模型仍是黑盒子。FedXAI 試圖將可解釋性整合進聯邦學習生命週期,透過多維度分類法分析模型解釋技術與隱私保護的共存路徑。研究指出該技術在醫療與金融等高風險領域至關重要,但目前仍面臨非 IID 數據導致的解釋不一致及缺乏標準化評估指標等挑戰,將影響未來可信 AI 的部署。
深度分析
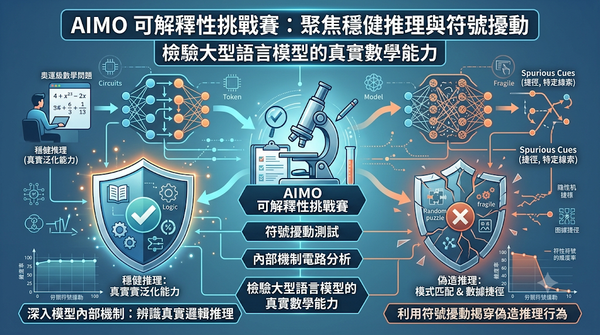
面對大型語言模型在數學基準測試中的高分,研究人員啟動 AIMO 可解釋性挑戰賽,旨在區分真正的邏輯推理與偽造的捷徑。該賽事透過提供奧運級數學問題及其符號表示,要求參賽者分析模型內部機制以辨識穩健推理。初步測試顯示,即使是前沿模型在面對簡單的符號擾動時,正確率也會大幅下降。這將推動 AI 可解釋性研究,確保高風險推理系統的可靠性與泛化能力。

速報
本研究以 GitHub 上 2,991 個開源專案為樣本,觀察在採用首個自動化機器人前後兩年內的團隊動態。研究將機器人視為團隊成員,測量重複合作、社會記憶與角色分化三項組織能力,並以衝突連鎖與產出獨特性作為成效指標。結果顯示,機器人採用後,團隊的重複協作次數提升、對機器人的辨識度增加,衝突發生次數下降,且產出更具獨特性。

深度分析
隨著代理式人工智慧可自行執行工作,傳統資安保險已不足。研究提出以自主層級、操作權限、治理成熟度與依賴集中度構成的風險狀態模型,將其映射至事件機率與保費計算,驗證在醫療協調案例中可區分可保與不可保範圍並提供定價依據。此框架亦揭示保險可作為AI營運成本與監管工具,未來將影響業者的風險治理與商業模式。

深度分析
隨著城市資料多樣化,傳統多模態模型因假設跨模態一致而易失準。研究提出UrbanAgent,將每種資料視為獨立代理人,透過協同推理與工具增強取得外部證據,於碳排、GDP與人口預測上提升約8.1%R²,顯示在未見城市也具備良好通用性,為智慧城市規劃提供新方向。
深度分析
隨著資料貢獻者要求刪除的合規需求提升,OriginBlame提供記錄與token級別的資料溯源,透過三層內容位址架構將作者身分自資料處理管線傳遞,能精準產生遺忘集合,實驗顯示相較於檔案級工具可將過度刪除降低至原來的千分之一,同時對模型未學習效能提升約四成。

深度分析
自動形式化正從翻譯單一自然語句,擴展至構建完整的理論知識庫,涵蓋公理、定義與證明等互相依賴的層次。此技術能快速產生高品質的形式化資料,並提升 AI 推理與錯誤檢測能力。未來若解決等價檢查與評估問題,將促進數學、科學與工程領域的大規模驗證與新發現。

深度分析
研究指出,Mycelium透過主動共享上下文圖即時連結人類與AI代理人的科學資訊,提升跨領域協作效率。相較於AWS OpenSearch Serverless的即時查詢層Mycelium更能保留上下文證據溯源。實驗顯示,較單一大型模型可加速發現、降低token消耗,預期重塑企業AI代理人部署與供應商格局。

深度分析
研究以 Belnap 四值型意向一階邏輯為基礎,加入機率計算與最大熵神經網路,提升機器人自我推理與不確定句子處理能力,展示了在強 AI 方向的可行性。作者亦提出全域與局部對稱轉換保護知識庫,並以 Shannon 最大熵推導機率密度,由神經網路即時產生,為未來 AI 安全與可解釋性提供新視角。

深度分析
隨著 AI 代理需要跨會話保存任務狀態,Oracle 推出以 Oracle Database 為基礎的 Agent Memory,提供從訊息擷取、摘要、篩選到語意檢索的完整生命週期管理。實驗顯示在 LongMemEval 基準上達 93.8% 正確率,且使用的 token 數僅為傳統平面歷史的十分之一,顯著提升效能與治理。