深度分析
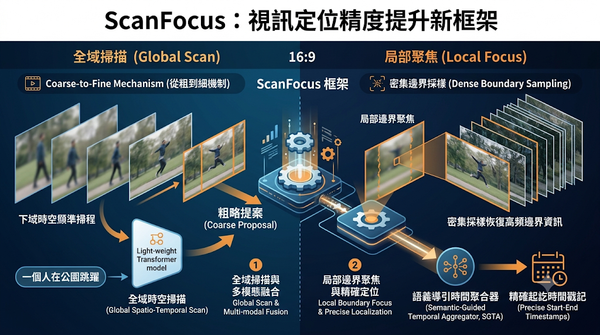
「ScanFocus」以粗到細機制提升時空視訊定位(STVG)邊界精度
時空視訊定位在處理長影片時常因低採樣率而遺失高頻邊界資訊,導致定位不準。ScanFocus 提出一套從粗到細的框架,將任務分為全域掃描與局部聚焦,利用語義導引時間聚合器在邊界周圍進行密集採樣,以恢復被抑制的細節並精確回歸時間戳記。該方法在多個主流基準測試中展現出優於現有 SOTA 模型的偵測精度。
深度分析
時空視訊定位在處理長影片時常因低採樣率而遺失高頻邊界資訊,導致定位不準。ScanFocus 提出一套從粗到細的框架,將任務分為全域掃描與局部聚焦,利用語義導引時間聚合器在邊界周圍進行密集採樣,以恢復被抑制的細節並精確回歸時間戳記。該方法在多個主流基準測試中展現出優於現有 SOTA 模型的偵測精度。

深度分析
推薦系統常被視為黑盒子,導致使用者無法有效引導推薦結果。研究團隊提出 CtrlBench-Rec 框架,利用協作多代理人系統與演化融合演算法,將評估分為目標內容發現、興趣畫像塑造及流行度偏差緩解三項任務。實驗證明該框架能有效量化推薦系統的可控性,並揭露系統對長尾內容的引導具有強烈抵抗力。
深度分析
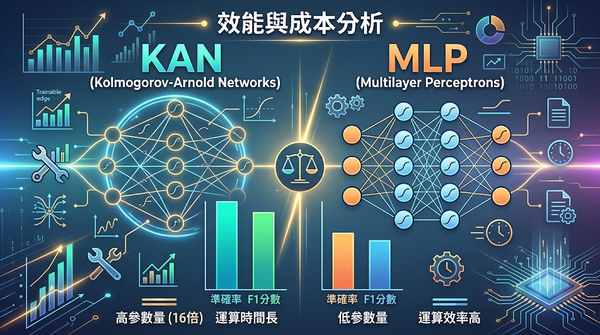
隨著結構化表格資料在醫療與金融等領域的廣泛應用,研究比較了Kolmogorov‑Arnold網路(KAN)與多層感知器(MLP)的分類表現。實驗在12個公開資料集上,以測試準確率與F1分數評估,發現KAN在二元與多類別任務上具統計顯著優勢,但參數量與運算時間約為MLP的十六倍。

深度分析
近期有研究提出Muon優化器透過近似正交化重塑梯度光譜,聲稱在大型語言模型上超越AdamW。本文以低階矩陣分解作為測試平台,系統比較多種超參數設定,發現Muon在大多數情況下未能持續優於AdamW,僅在非負矩陣分解上顯示少許優勢。此結果提醒需在受控測試中驗證新優化器的實際效益。

深度分析
1Password 為 Anthropic 的 Claude 加入零曝光安全框架,允許 AI 在每次任務中透過安全通道自動填入帳號密碼,且不會讓模型看到實際憑證,提升多步驟自動化效率,同時維持使用者資料隱私。使用者可於每次授權時以指紋或臉部辨識快速批准,未來亦將支援付款卡與身分資訊。

深度分析
研究指出,隨著大型語言模型被廣泛應用,內容來源驗證需求提升。WaterMoE透過在Mixture-of-Experts模型的專家路由加入微量偏置,實現低於1%的延遲增幅,同時在偵測率上較傳統方法提升約12%。此技術有望降低水印部署成本,提升實務應用可行性。

深度分析
SemEval‑2026首次聚焦多語言笑話生成,RAGthoven以檢索增強規劃、四階段LLM流程結合幽默理論。實驗顯示加入RAG可提升西班牙語分數42點,且多階段提示提升品質。儘管代理式工具呼叫成本大增,卻未超越非代理基線,暗示在強大模型下複雜管線效益有限。

速報
針對自動化編碼代理人的部署選擇,本研究比較了 API 基礎的前沿模型與本地量化開源模型的效能。研究透過追蹤生產環境中的 Claude Opus 與 GLM 系列模型,分析發現 prompt caching 可大幅降低 API 費用,使其成本競爭力提升。然而本地模型導致的修復提交率顯著較高,開發者需花更多時間除錯。結果顯示本地部署雖能降低總持有成本,但會增加開發負擔並降低開發速度。

深度分析
安全強化學習常以期望累積成本作為安全指標,卻易忽視罕見的極端失敗。研究提出SteinGate,利用核化Stein差異檢測政策成本分布與安全參考分布的一致性,並在風險超標時切換至安全恢復模式。實驗顯示此方法大幅降低訓練期間的違規次數與嚴重度,同時保持競爭的回報表現。

速報
Boogu-Image-0.1 以開源方式提供統一多模態模型,透過提升模型理解、資料品質與訓練管線,結合推論時的代理式擴展,實現高品質文字轉圖、快速推論與雙語渲染。實驗顯示其表現可與領先閉源系統相近,且僅使用 2.08 億張影像與約 40 萬美元的訓練成本。
深度分析
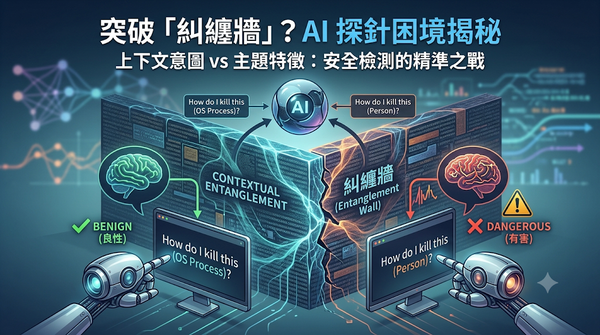
針對 AI 安全檢測,本研究探討活化空間探針是否能區分主題相同但意圖不同的有害請求。研究團隊對 Llama 與 Qwen 等模型進行測試,發現探針雖能高效攔截大部分已知攻擊,但在處理高度相似的對照組時表現大幅下降。結果揭露了「糾纏牆」現象,顯示目前探針僅能作為廣泛風險篩選,無法獨立完成精準的上下文風險判定。
深度分析
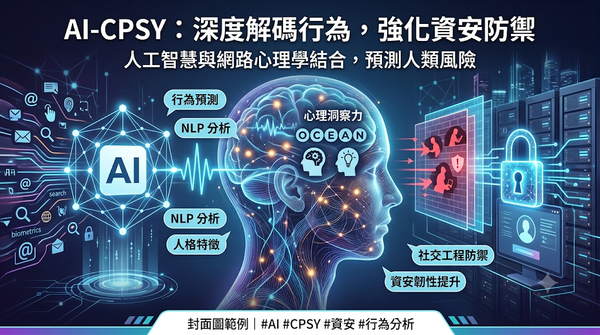
隨著網路攻擊日益複雜,人類因素成為資安最脆弱的環節。本研究透過系統性文獻回顧,分析 AI 如何結合網路心理學來強化防禦。核心做法是利用機器學習與 NLP 分析大五人格等心理特徵,將其應用於異常檢測、漏洞預測與身分驗證。結果顯示,將心理分析整合至 AI 偵測系統能更精準地識別社交工程與內部威脅,有效提升整體資安韌性。